
Handling Large proofs on Celestia by chunking blobs

We've been building the Via Network to post data to Celestia for Data Availability guarantees. We knew there were limits, and we would hit a hard wall. For us, that wall came when our proof data exceeded what we could safely post in a single operation.
Here, we go over how we solved the problem of handling arbitrarily large proofs. Not with clever compression tricks or pruning strategies, but with a time-honored engineering approach: "When the data is too big, chop it up!"
Via Network is a modular sovereign, validity-proof zk-rollup for Bitcoin with a zkEVM execution layer using Celestia DA. It was posting batch data and proofs to Celestia, inscribing commitments to Bitcoin as everything worked as designed.
Everything worked fine until our dispatcher started failing. Not with a network error or a transient timeout, but with a hard rejection from Celestia, showing the "blob is too large"
This wasn't a problem that we would kick down the road. Every failed proof submission prevented batches from being finalized, thereby hindering our network's progress.
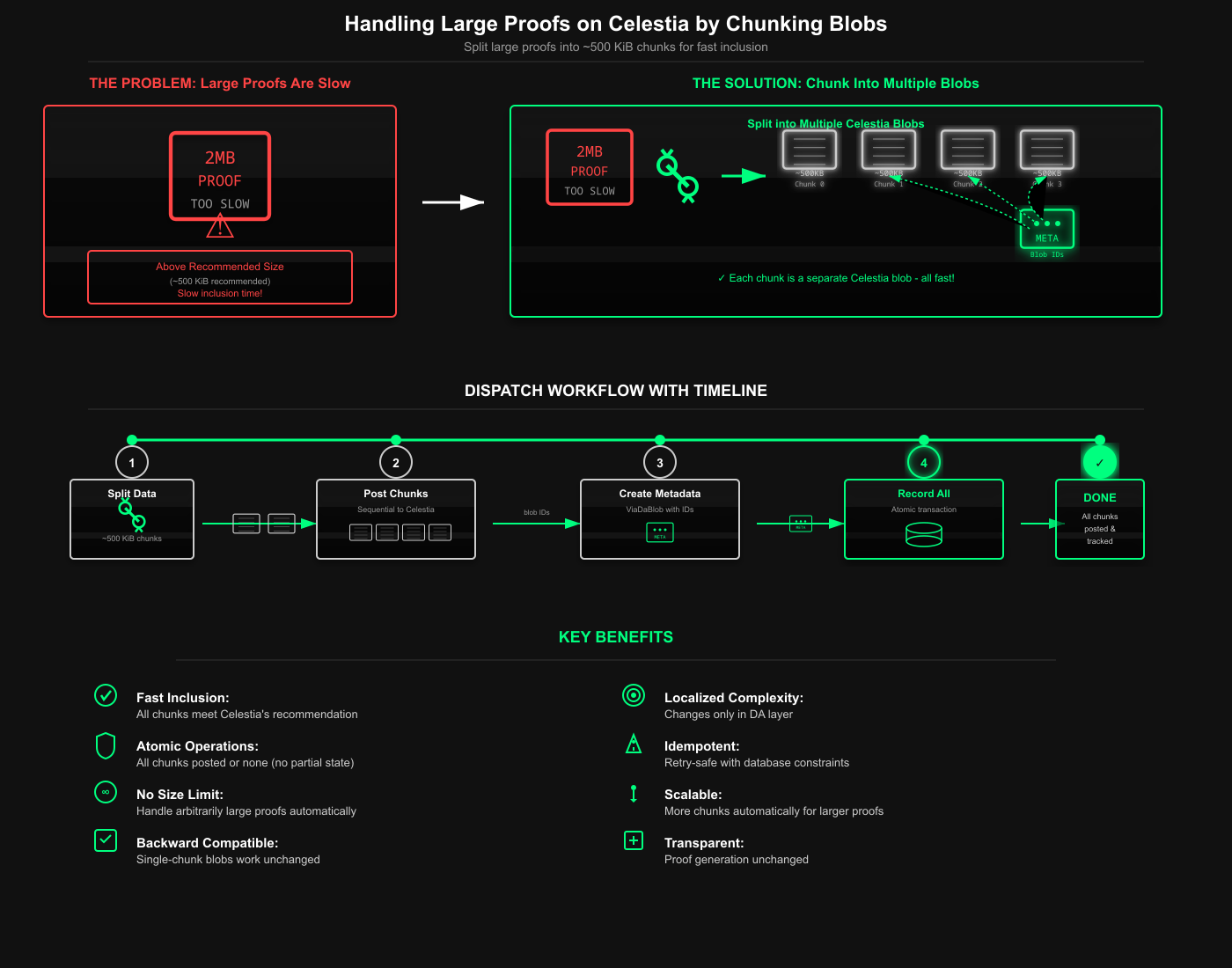
The system needed to handle arbitrarily large blobs. While Celestia permits blobs up to approximately 1.8-2 MiB, they recommend keeping blobs under ~500 KiB for faster inclusion. Larger blobs might face delays because validators tend to prioritize smaller, quicker-to-process blobs.
The impact rippled through the entire system. Our Bitcoin inscription aggregator, which requires both batch and proof data to be available on Celestia before it can create Bitcoin inscriptions, would stall. The external nodes pulling data for verification would fail to reconstruct the state. Every component that assumed "one batch = 1 blob" would need some reconsideration.

PR 290
When hitting a size limit, the options are always the same. Make your data smaller or split it into pieces.
We couldn't compress our data with a pointless compression technique, because ZK proofs are cryptographic outputs with high entropy! It's basically random-looking binary data with minimal redundancy or patterns. Standard compression algorithms like zstd or gzip yield nearly 1:1 ratios, resulting in marginal compression gains at best and wasting CPU cycles.
The chunking approach was more attractive.
- It's transparent to the proof system, so we could keep using existing proofs.
- It's backward-compatible, meaning that single-chunk blobs (~500 KiB) would work exactly as before.
- If the proofs get even larger in the future, the system will automatically create more chunks.
The trade-off is added complexity in the DA layer and the client reconstruction logic, but it is one we are willing to make it.
Some familiar with Celestia might wonder why ~500 KiB chunks when Celestia allows ~1 MiB per blob? We stay well below the protocol cap to leave headroom for share framing, commitment overhead, and base64/hex encoding that inflates on-wire size. This also makes retries cheaper and improves scheduling reliability under varying data square sizes.
Either all chunks of a blob are on Celestia with inclusion proofs, or the batch is not considered finalized. There is no "partial availability" state. This required careful coordination between the dispatcher, who creates chunks, and the aggregator, who checks for completion before moving forward with Bitcoin inscriptions.
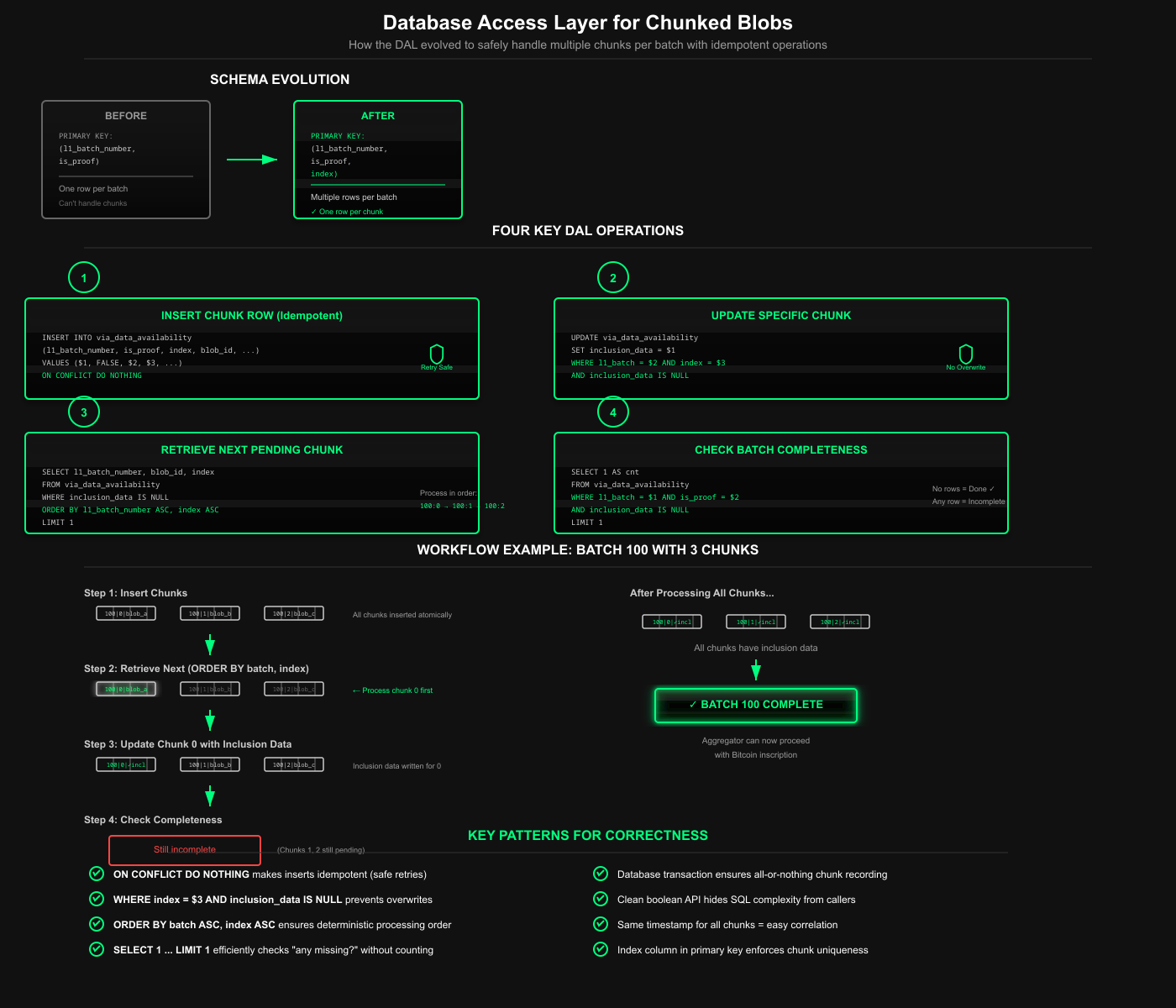
Database scheme
Let's start at the foundation, the database. The via_data_availability table originally had a simple structure: one row per L1 batch, tracking whether it's proof data or batch data, storing the blob ID and inclusion proof. The primary key was just (l1_batch_number, is_proof). This worked perfectly when one batch meant one blob.
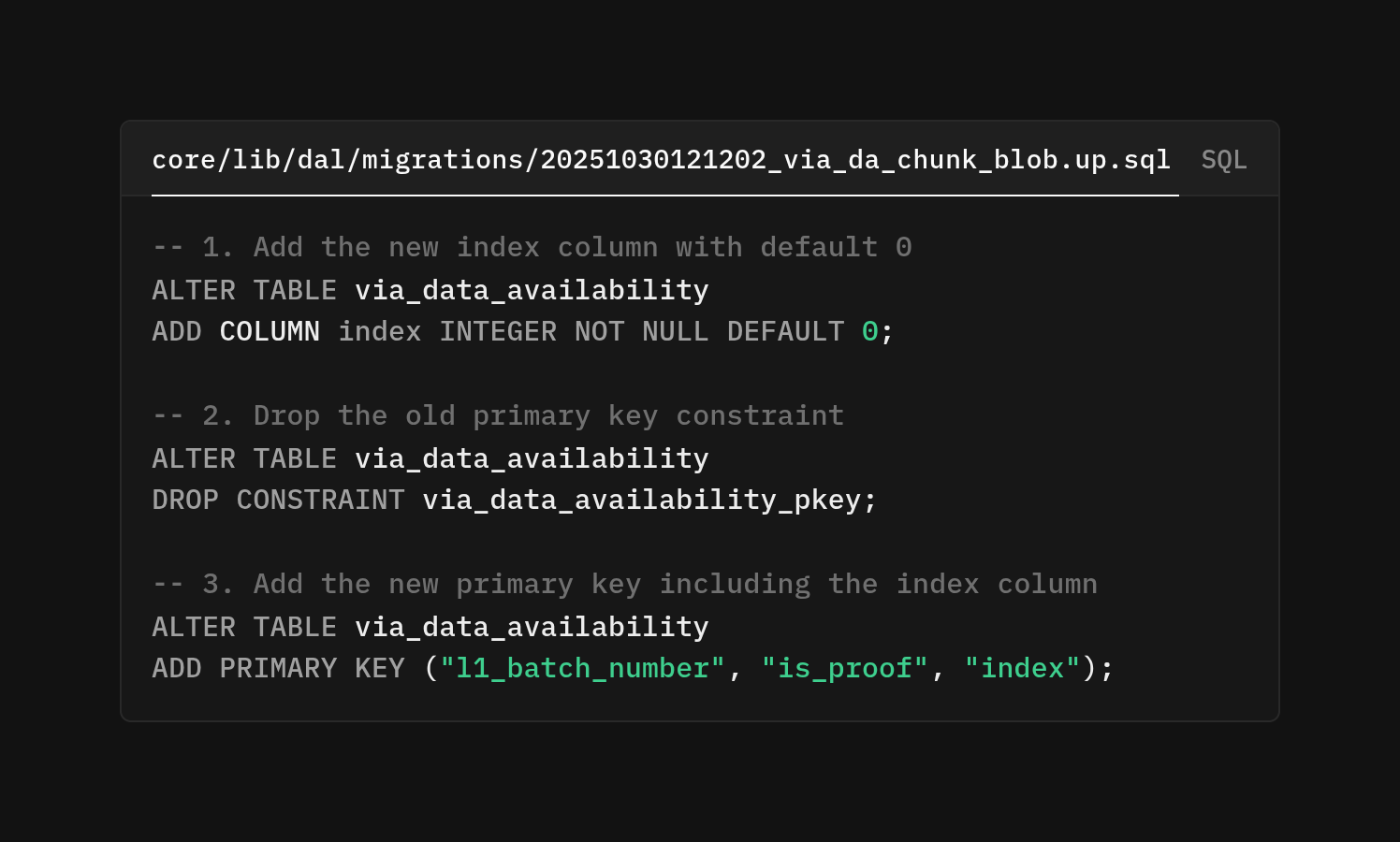
The new index column defaults to 0 for existing rows, maintaining backward compatibility.
Then we remove the old two-column primary key and recreate it using three columns that enable multiple blobs per batch, each identified by its index. The index isn't just metadata, as it's part of the primary key, which means the database enforces uniqueness at the chunk level, allowing our queries to retrieve chunks in order efficiently.
Type System Extensions
Before we could implement chunking, we needed types to represent chunked data, because when storing chunks on Celestia, you face the problem of how to package the pieces so you can find them again later.
The new ViaDaBlob structure encodes both the chunk count metadata and the actual data payload.
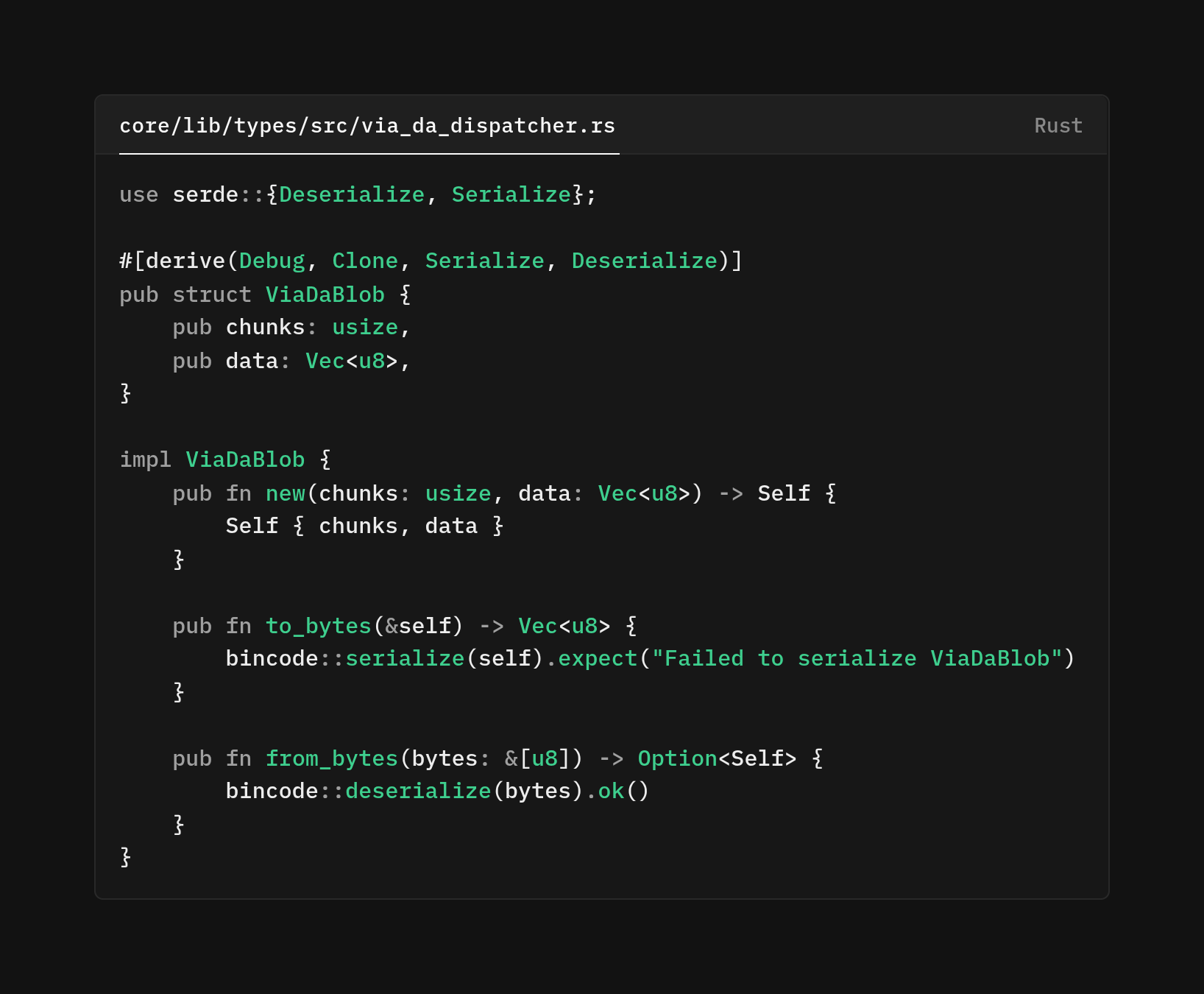
The ViaDaBlob is a wrapper that holds metadata. Thechunks are how many pieces and data the actual bytes. For a single blobs, chunk is 1 and data is the full payload. But for multi-piece blobs, the last envelope plays a special role because it doesn't contain any chunk data. Instead, it's a table of contents listing the addresses (blob IDs) of all the other pieces.
We're using bincode. Bincode produces compact binary representations without the overhead of field names or schema descriptors, for data that's going to be posted to a blockchain where every byte costs gas (or, in Celestia's case, contributes to namespace congestion).
The from_bytes method returns Option<Self> rather than panicking on failure. If we somehow receive corrupted data or data from a future version of the code that serializes differently, we want to handle it 'gracefully' rather than crashing the node. The caller can decide whether to retry, log an error, or fail the operation based on what happens.
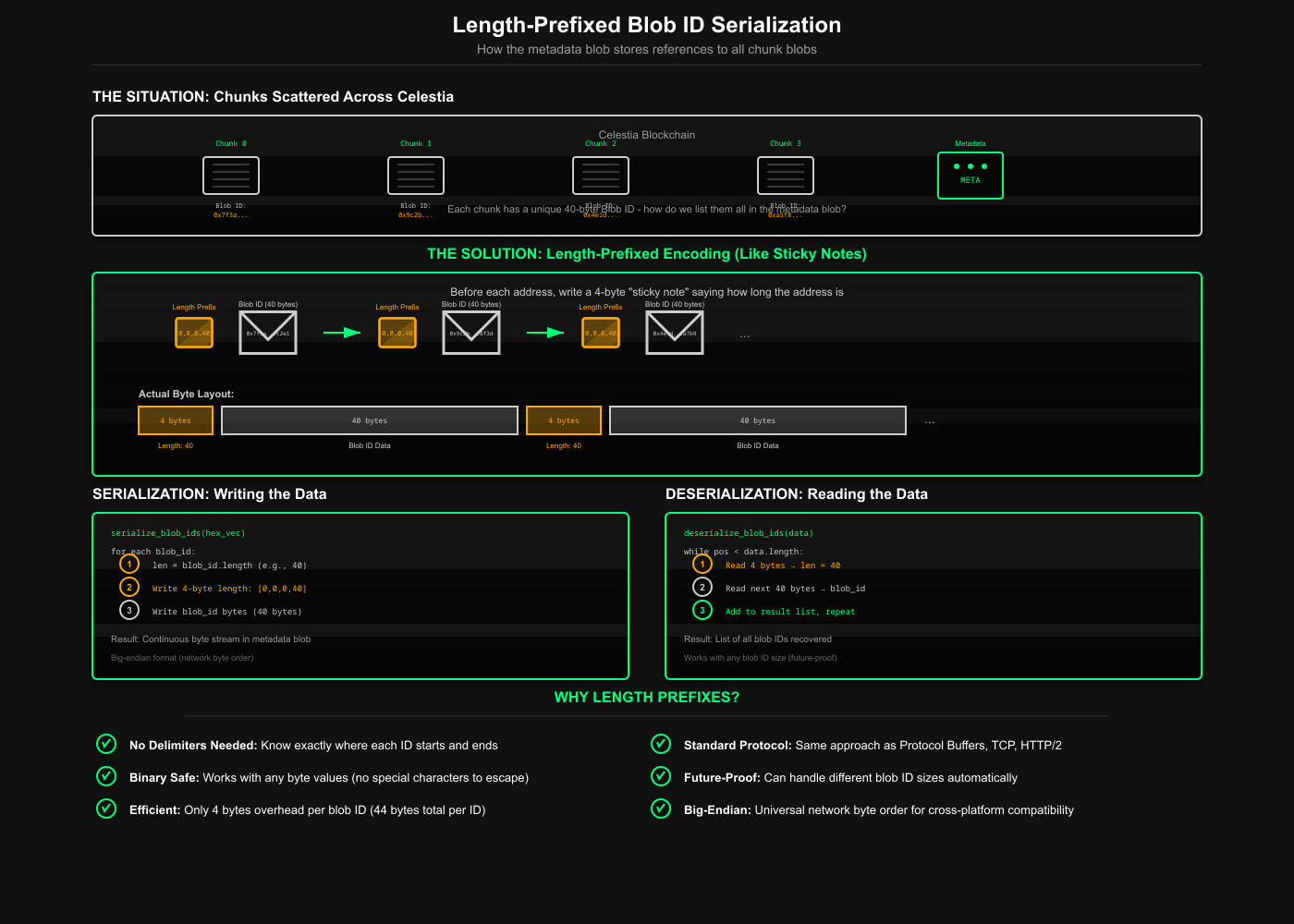
Once we've split our giant blob into chunks and posted them to Celestia, we have a new problem. Those chunks are scattered across the blockchain like breadcrumbs. Each got its own unique address, a 40-byte blob ID linked to the data at block number with cryptographic proof.
Our final metadata blob needs to list all these addresses so anyone can find and reconstruct the pieces. We're basically building a list of addresses that someone else's code needs to read later. Maybe their code is written in Go, Rust, TypeScript, or even some future language that doesn't exist yet.
The solution is as old as time. Before writing each address, write a tiny 4-byte number saying "the next address is X bytes long." It's like putting a sticky note on each envelope saying "this package is 40 bytes" before stuffing it into the mailbox.
[0, 0, 0, 40] ← "Next address is 40 bytes"
[blob ID bytes...40 bytes total] ← The actual address
[0, 0, 0, 40] ← "Next address is also 40 bytes"
[blob ID bytes...40 bytes total] ← Another address
...
Here's how we serialize lists of blob IDs:
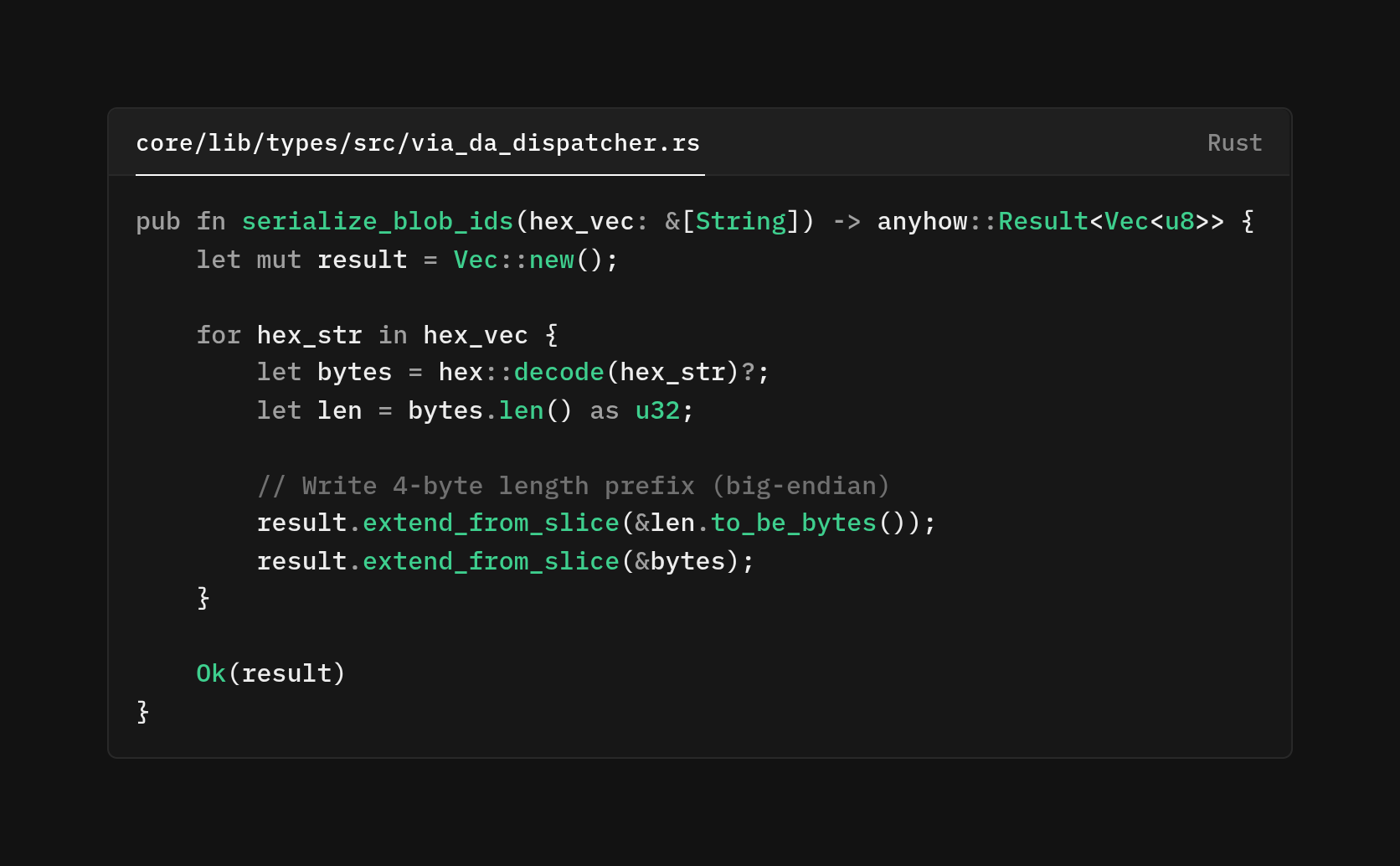
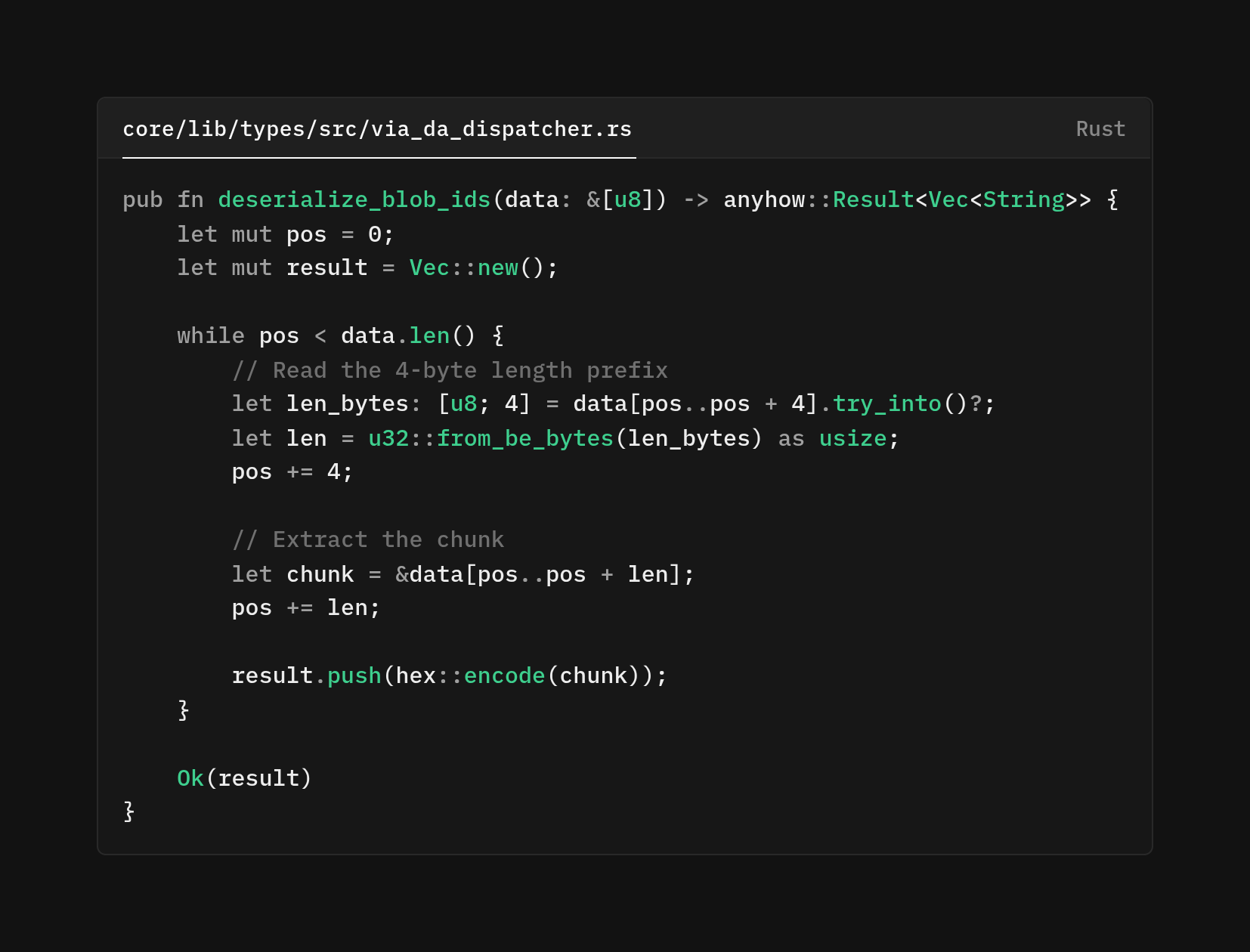
This function implements a simple length-prefixed encoding scheme. For each blob ID (a hex string), we decode it to bytes, write a 4-byte big-endian length prefix, then write the bytes themselves. This is how other protocols, like Protocol Buffers, use their wire formats. The 4-byte prefix means each chunk can be up to 4GB.
The deserialization walks through the byte array, reading length prefixes and extracting chunks
Database Access Layer for chunked blobs
With the schema and types in place, every database query that touches via_data_availability needed updating.
The old code inserted a single row per batch
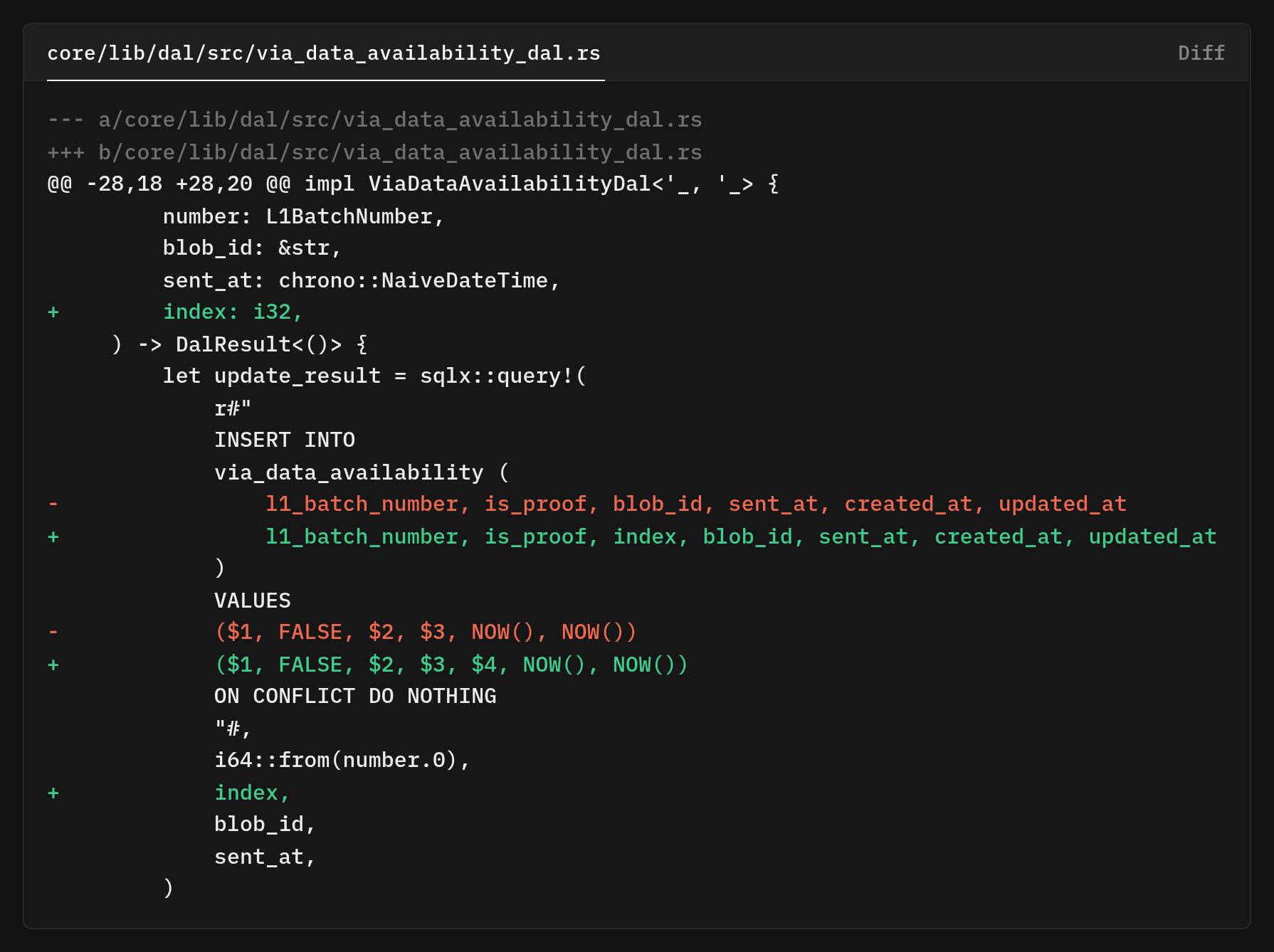
The insert_l1_batch_da method now takes a index parameter that identifies which chunk of the batch this blob represents. The ON CONFLICT DO NOTHING clause is important, it makes the insertion idempotent.
If we retry a failed dispatch operation, we won't create duplicate rows or cause database errors. The database ignores attempts to insert rows that would violate the primary key constraint.
Updating inclusion data follows the same pattern
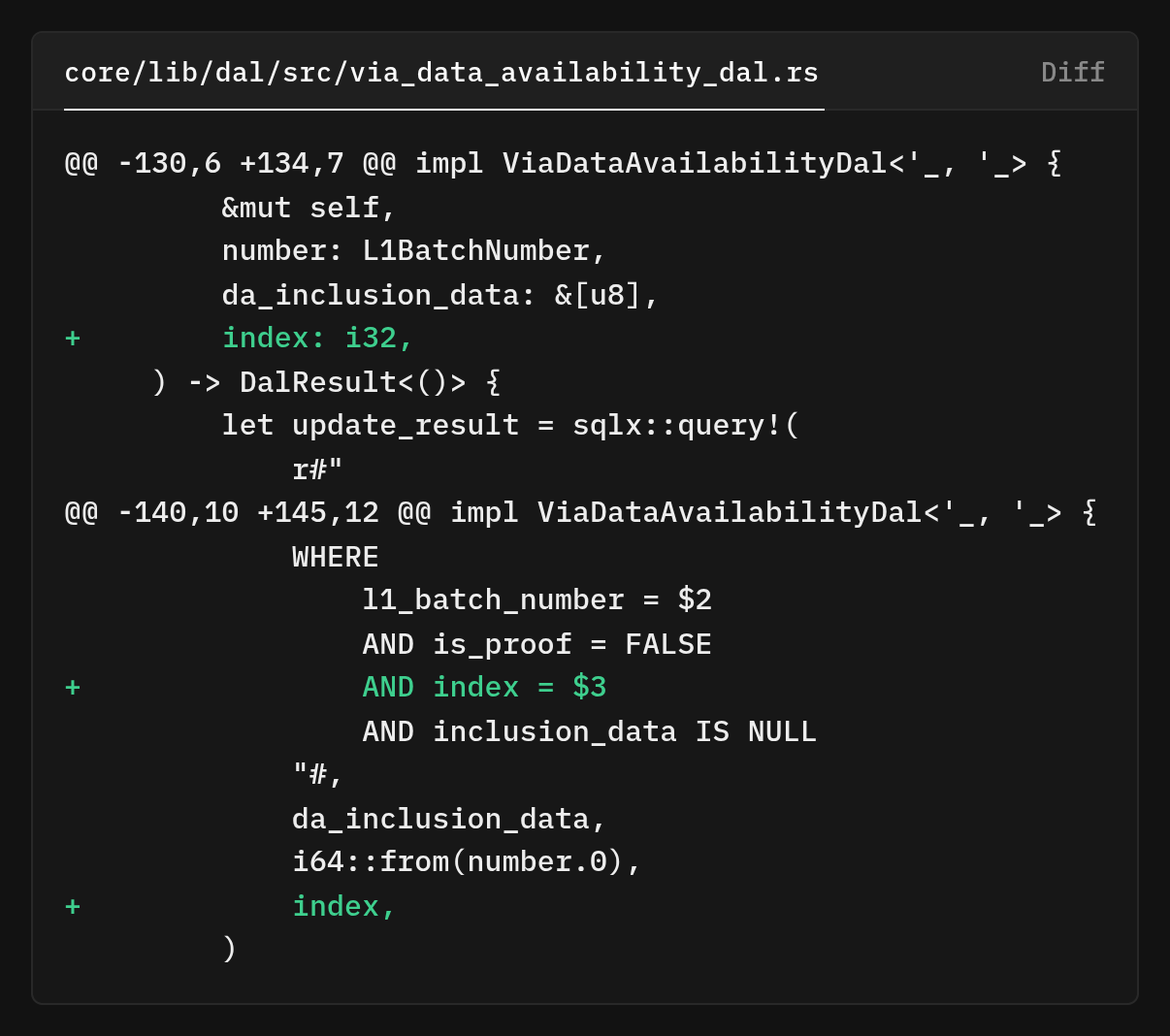
Adding AND index = $3 in the WHERE clause because without it, the UPDATE would modify multiple rows, but we only want to update a specific chunk. The AND inclusion_data IS NULL condition prevents overwriting existing data, avoiding corruption if a blob is processed twice.
The tricky part, retrieving blobs for inclusion in data processing. The old code assumed one blob per batch and used LIMIT 1
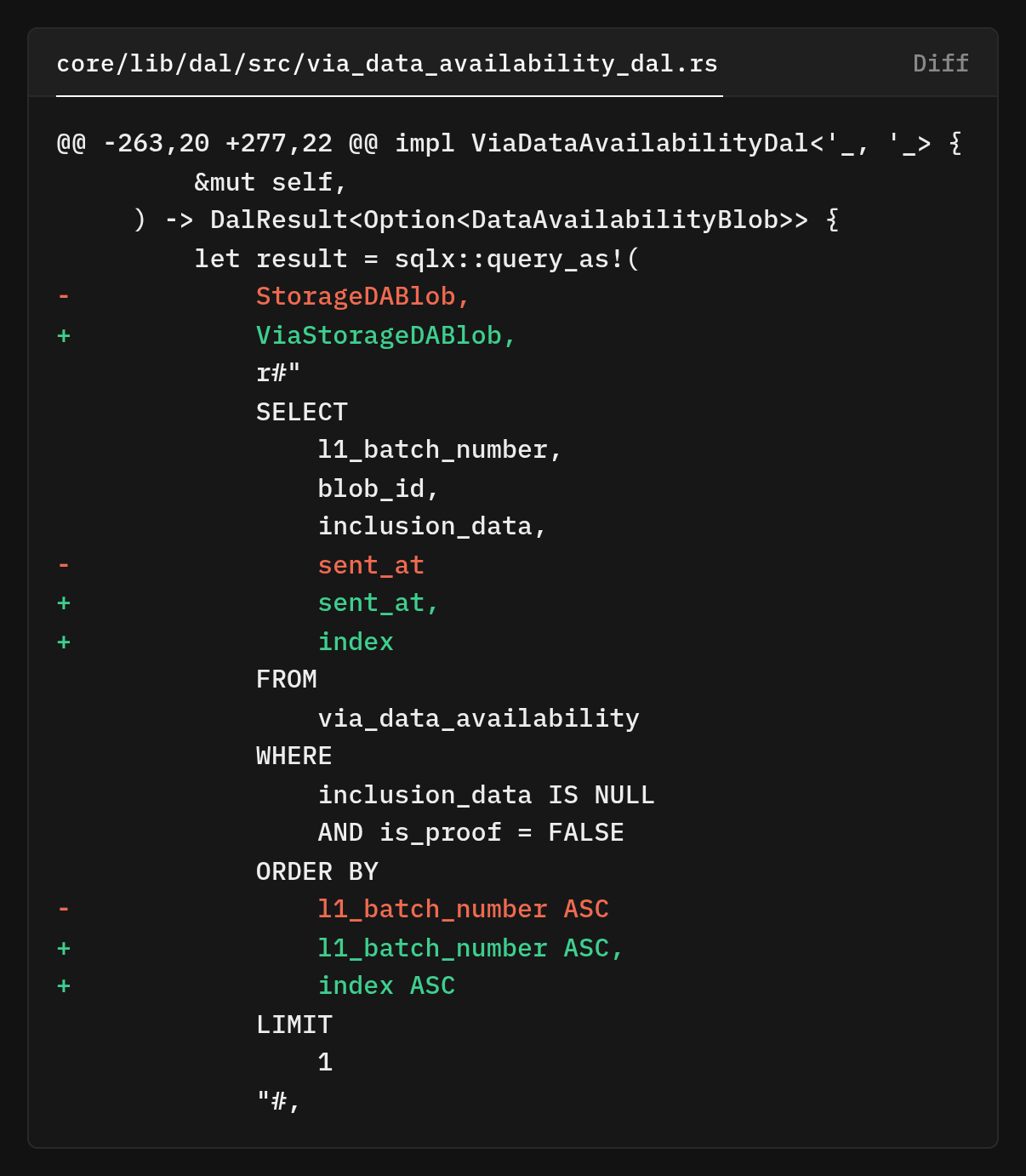
The new ordering l1_batch_number ASC, index ASC ensures we process chunks in the correct sequence. If batch 100 has chunks 0, 1, and 2 all waiting for inclusion data, we'll process them in order: 100:0, then 100:1, then 100:2.
This ordering matters because the inclusion data fetcher needs to know whether a batch has been fully processed before moving on, and processing chunks out of order would complicate that logic. The most interesting query addition is is_batch_inclusion_done, which checks if all chunks have inclusion data
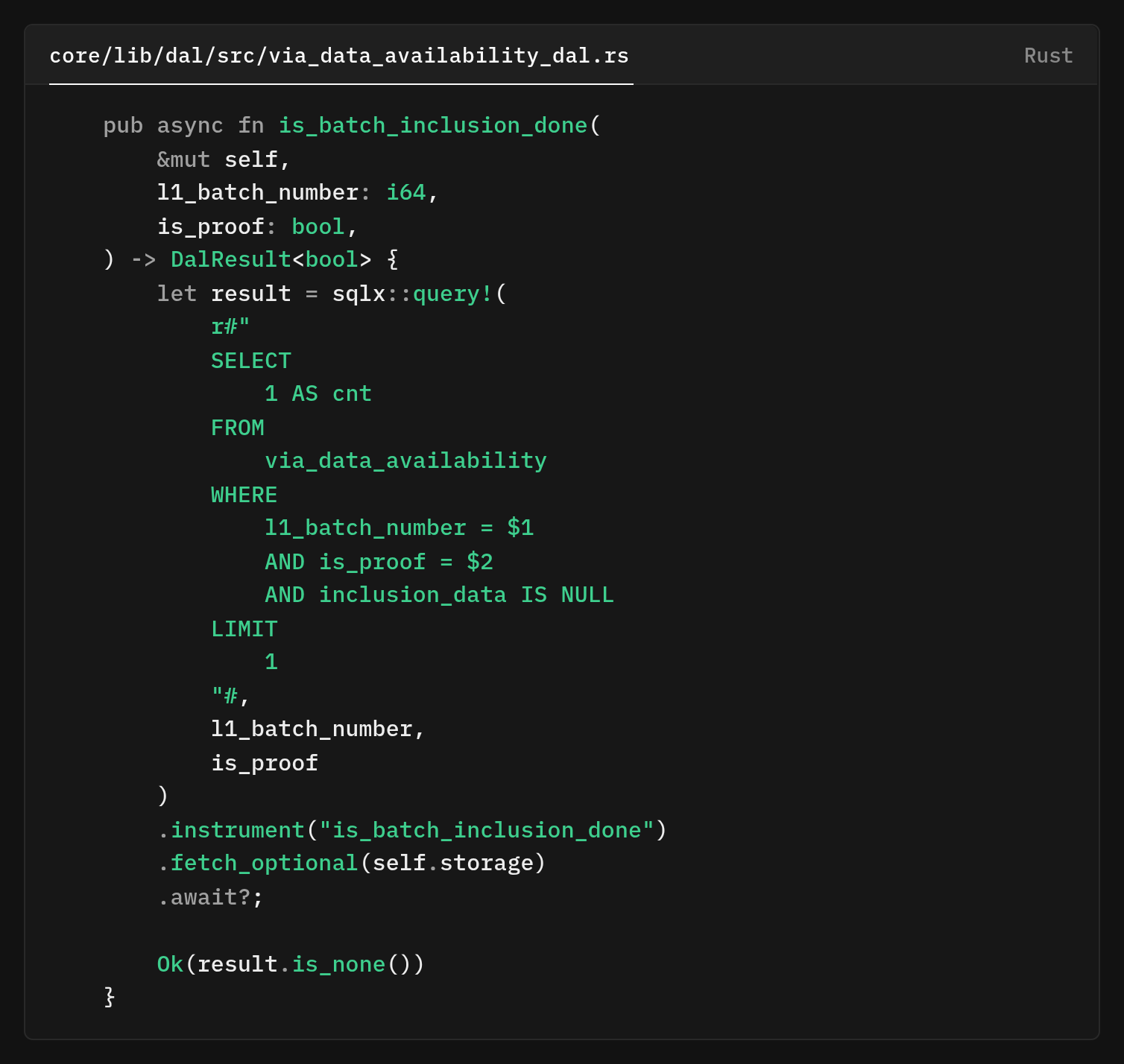
This function inverts the question from "do you have all the inclusion data?" to "do you have ANY missing inclusion data?" If no rows are returned, all chunks are complete. The LIMIT 1 optimizes performance by quickly checking for missing chunks.
The return type DalResult<bool> wraps the database operation in error handling, providing a clean boolean interface to callers.
Celestia Client Reconstruction
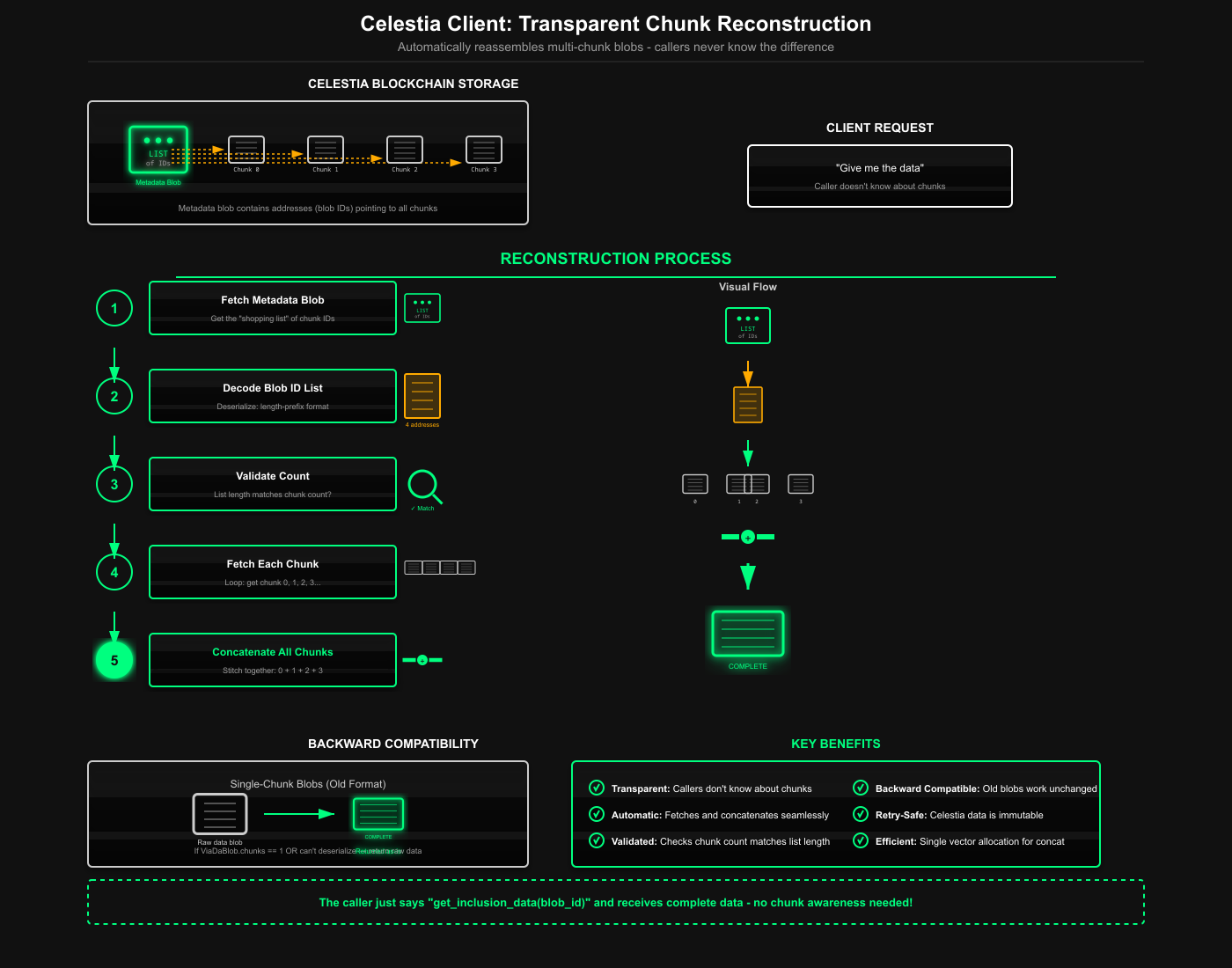
The Celestia client's job is to hide the complexity of chunking from callers. When asked for inclusion data via get_inclusion_data, it should return the complete reconstructed blob regardless of whether it was stored as one chunk or many
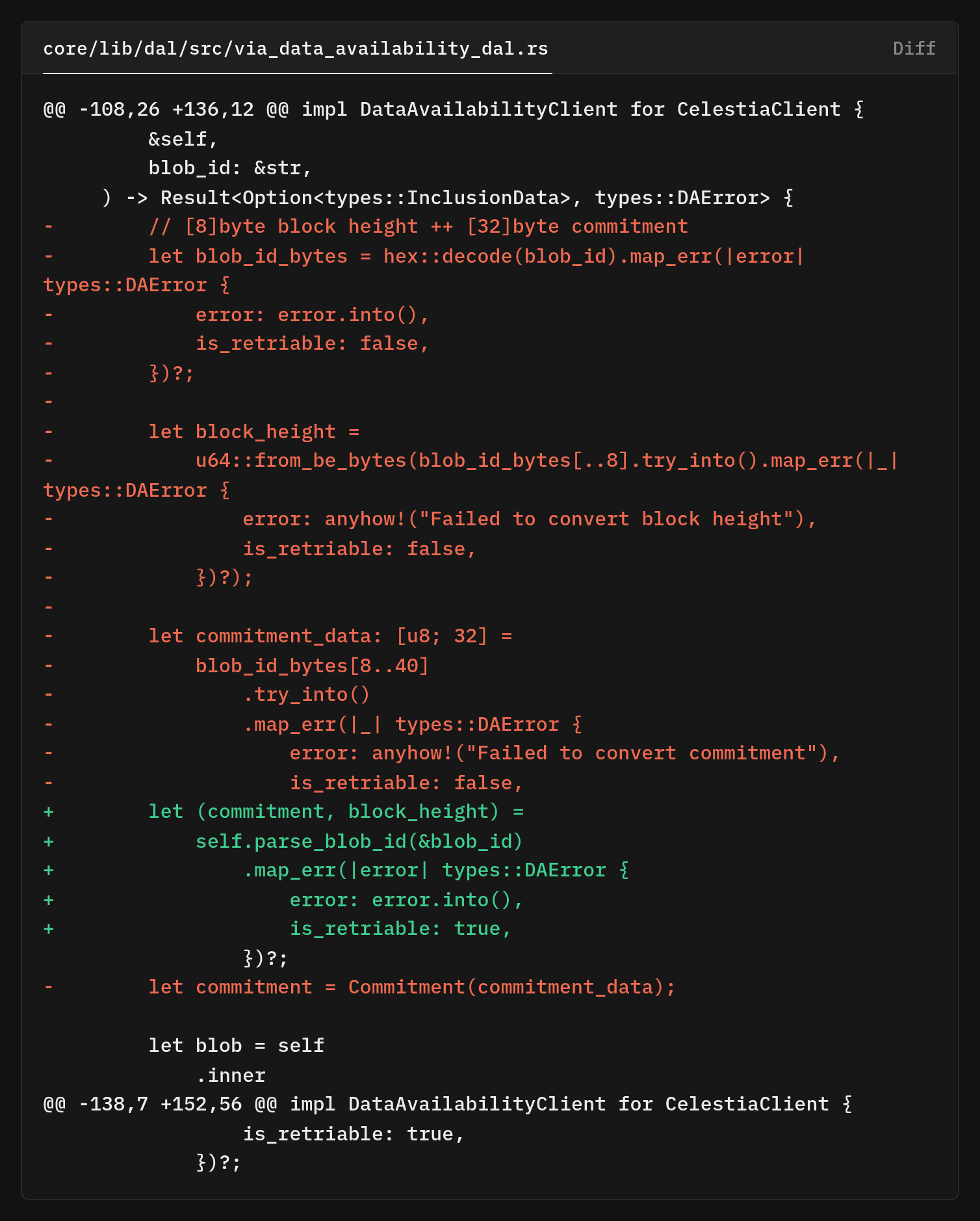
The refactored code first extracts the blob parsing logic into a helper method parse_blob_id. Parsing logic is reused when fetching chunk blobs, so factoring it out gets rid of duplication and makes the code easier to test.
The blob ID format is [8 bytes: block_height][32 bytes: commitment], a small 40-byte identifier that Celestia uses to locate blobs.
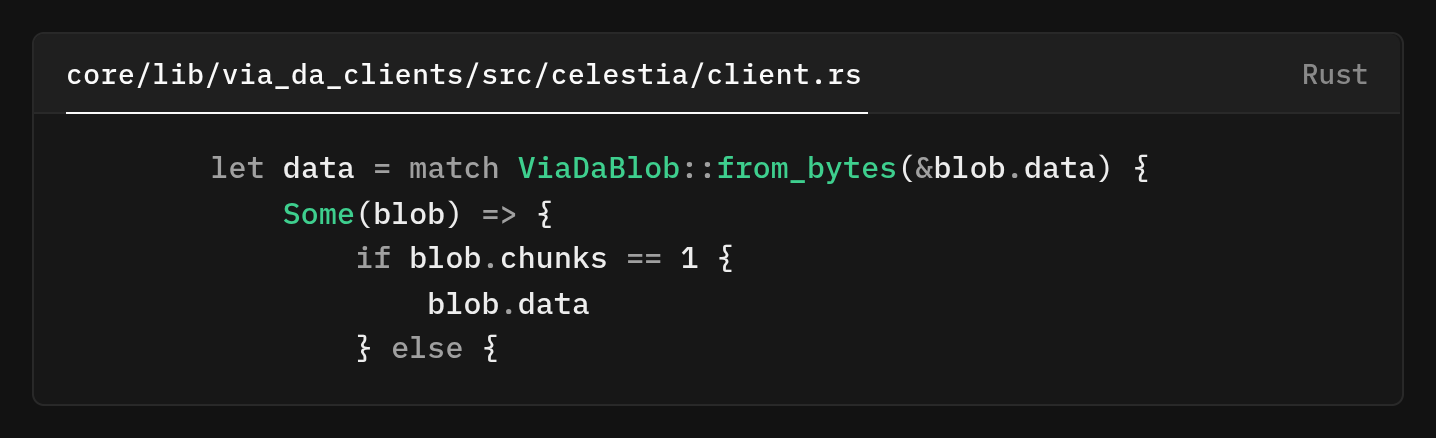
After fetching the initial blob, we attempt to decode it as a ViaDaBlob
If deserialization succeeds and chunks is 1, this is a single-chunk blob, we unwrap the data and return it. This maintains perfect backward compatibility with blobs created before chunking support was added. Old blobs won't deserialize as ViaDaBlob, so they fall through to the None arm, which returns the raw blob data unchanged.
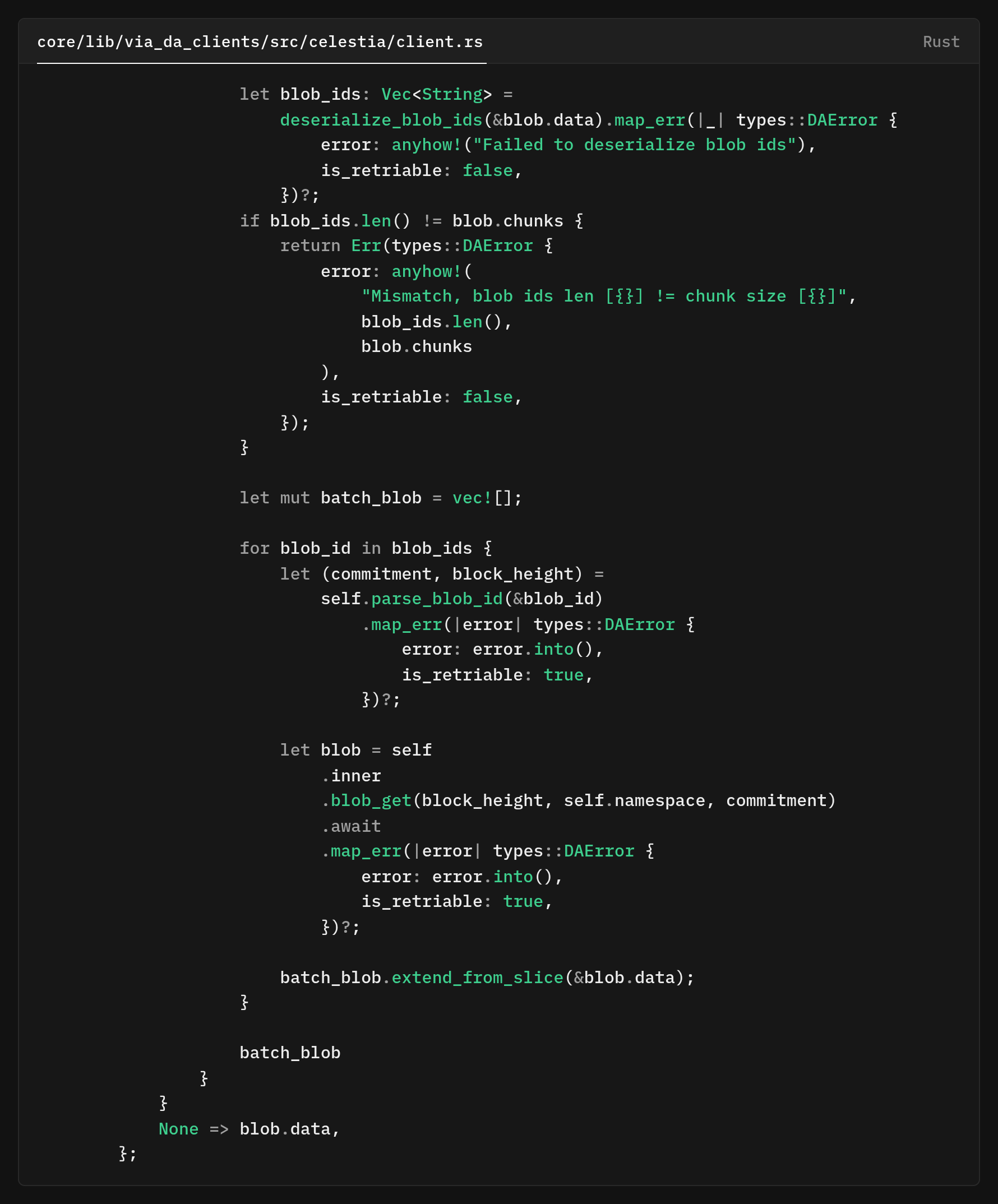
The data field in the metadata blob stores a serialized list of all chunk IDs. We deserialize and verify that its count matches the chunks field, catching corruption or errors early. If an incorrect blob ID list is posted, we return an error quickly rather than truncated or incorrect data.
We iterate through blob IDs, fetching and concatenating each chunk from Celestia. Using extend_from_slice is efficient, reusing the vector allocation instead of creating a new one for each chunk. This improves performance, especially with dozens of chunks for large proofs.
One small but important detail, all Celestia fetch operations are marked as is_retriable: true. This means if a chunk fetch fails due to network issues, the caller should retry the entire reconstruction process. This is safe because Celestia is immutable, as once a blob is posted, it will always be available at that commitment and block height. Retries won't cause data inconsistency.
The Dispatcher Chunking Engine
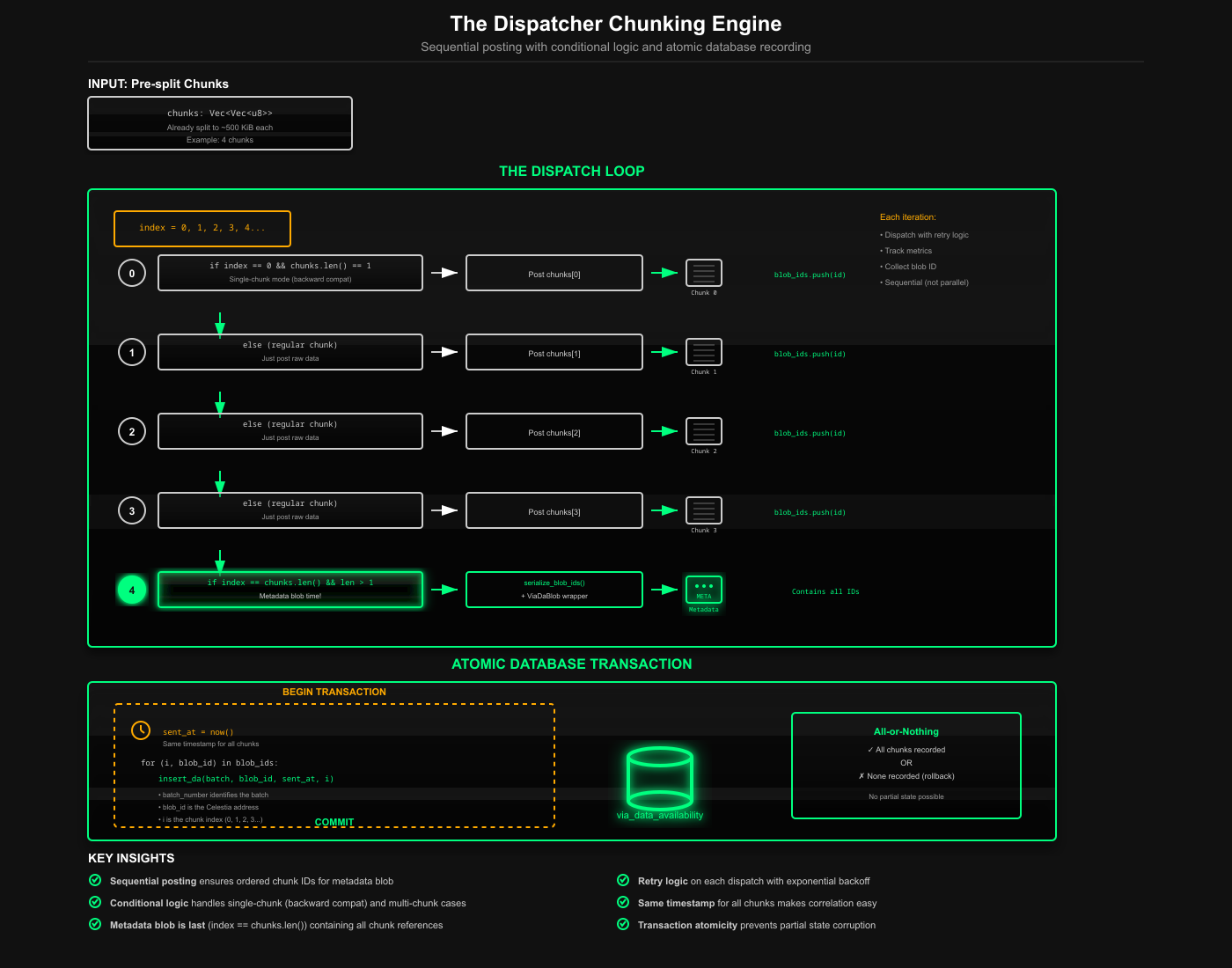
The DA dispatcher is where chunking happens during blob submission. This is the most complex part of the patch because it handles the splitting, sequencing, and atomic recording of chunks.
The new _dispatch_chunks method
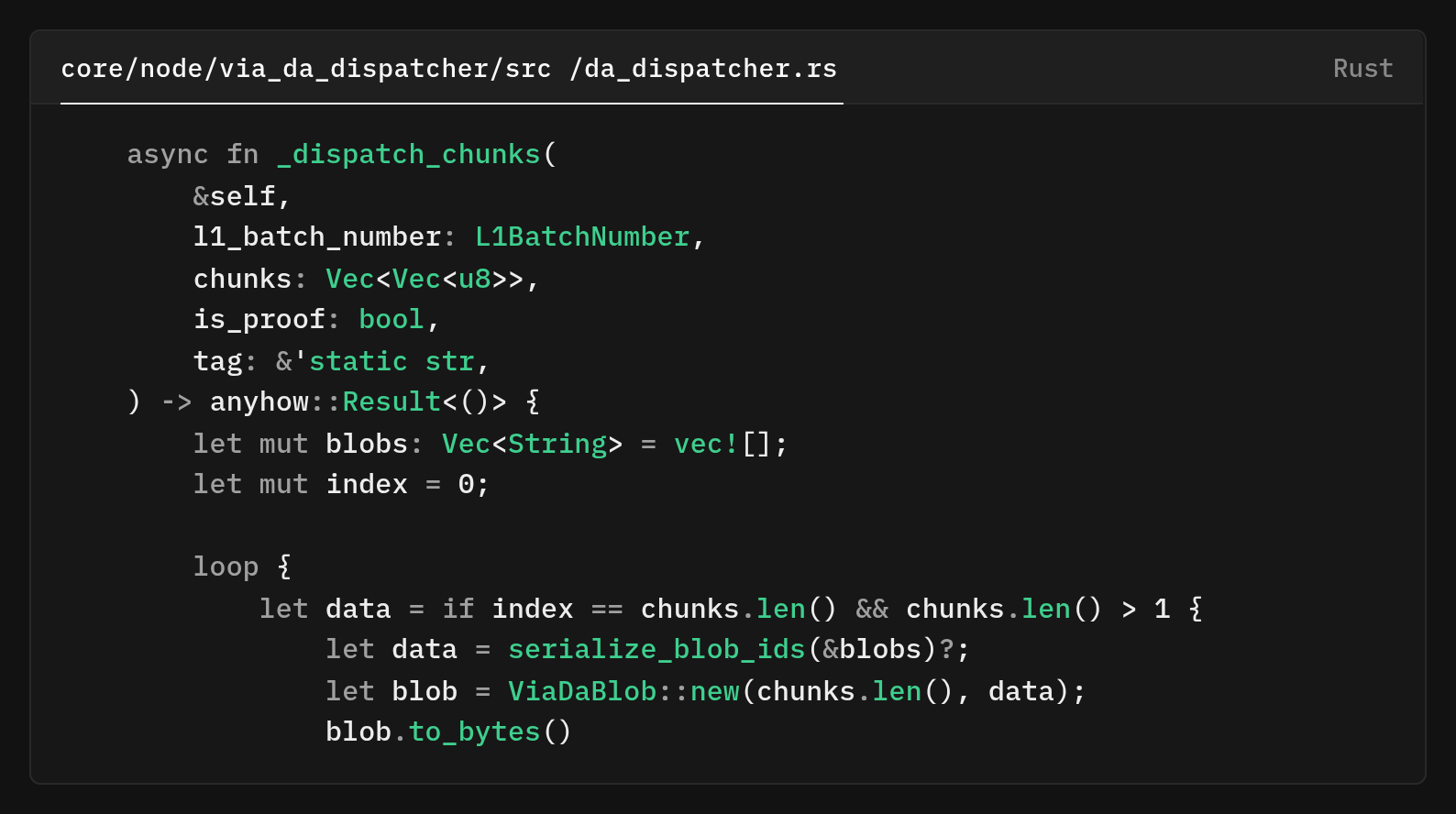
The method processes chunks (~500 KiB each) sequentially using a carefully crafted loop. On the final iteration (when index == chunks.len() and multiple chunks exist), it posts the metadata blob. It serializes blob IDs, wraps them a ViaDaBlob with the chunk count, and serializes that for posting.
After fetching the initial blob, we try to decode it as a ViaDaBlob
If this is a single-chunk blob (index == 0 && chunks.len() == 1), we wrap it in ViaDaBlob with chunks: 1 for forward compatibility. If all chunks and the metadata blob are posted, we break the loop.
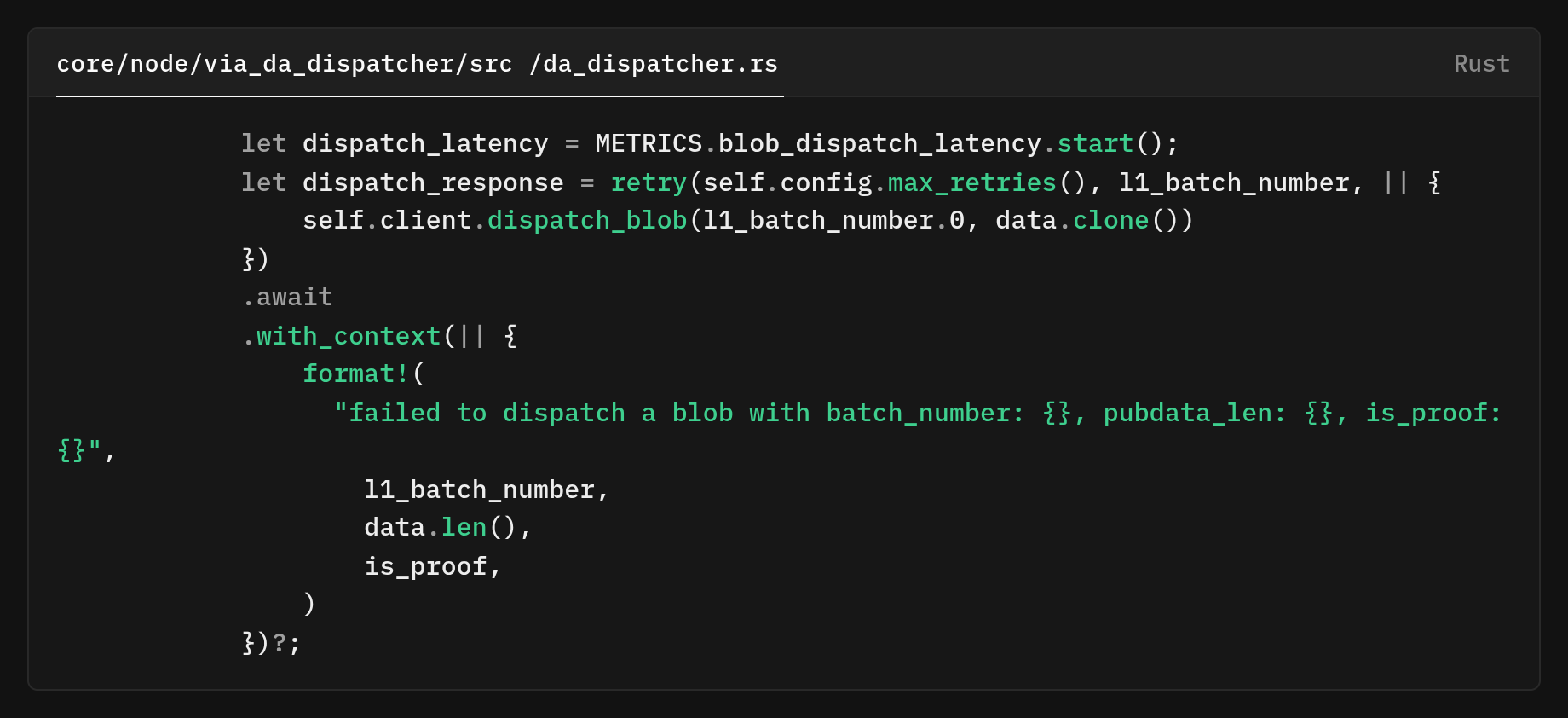
For regular chunk blobs (not the first or final), we use raw chunk data. Dispatch is wrapped in retry logic with exponential backoff, and we collect latency metrics. Error messages include batch number, data length, and proof data status for debugging.
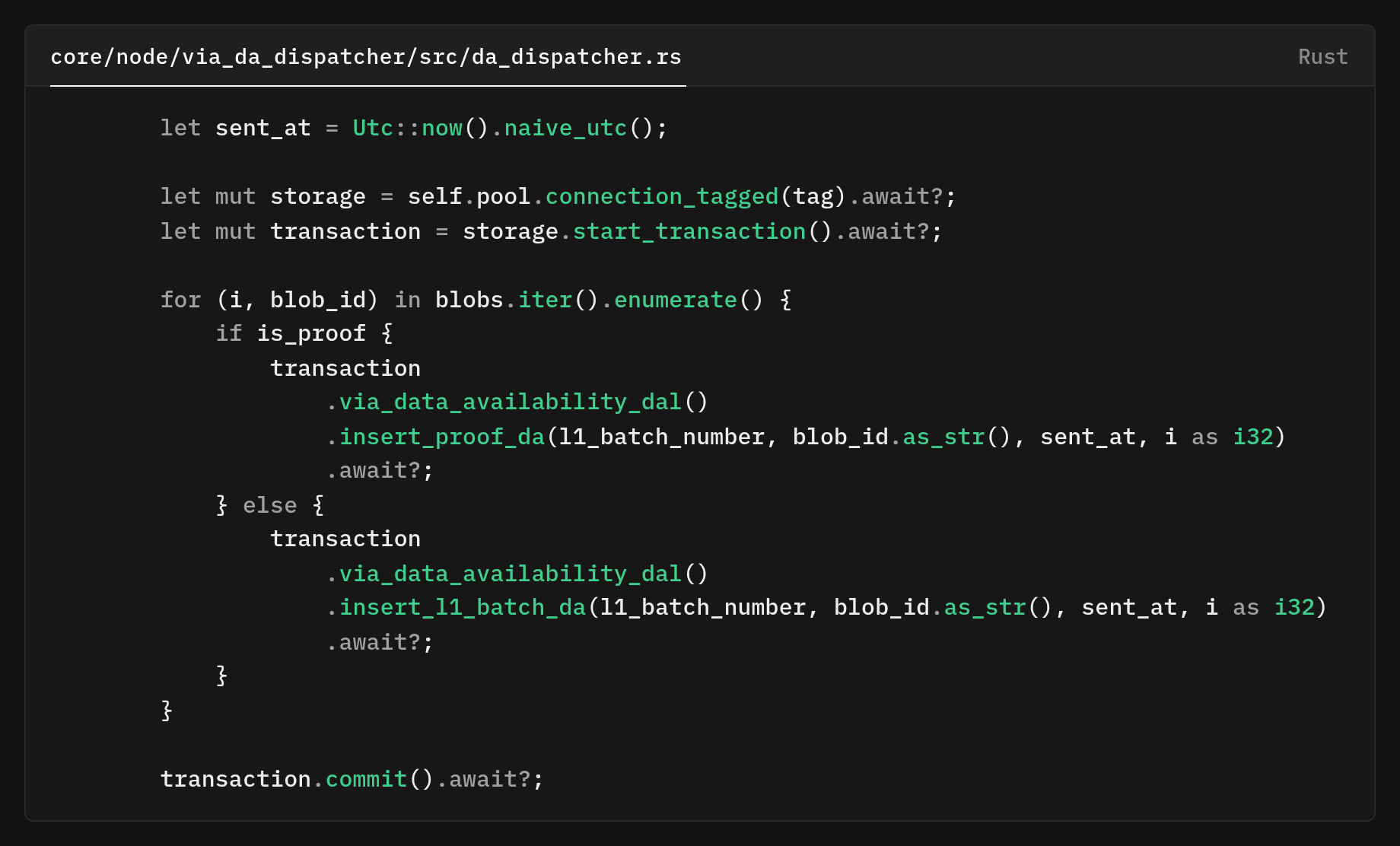
We use a database transaction to ensure all-or-nothing semantics, recording all chunks with their blob IDs and indices or none.
The timestamp sent_at is the same for all chunks, this is intentional. It represents when we began the dispatch operation, not when each individual chunk finished. Using the same timestamp for all chunks makes it easy to correlate them and understand that they belong to the same logical operation.
Bitcoin inscription aggregator proceeds once all chunks have inclusion data
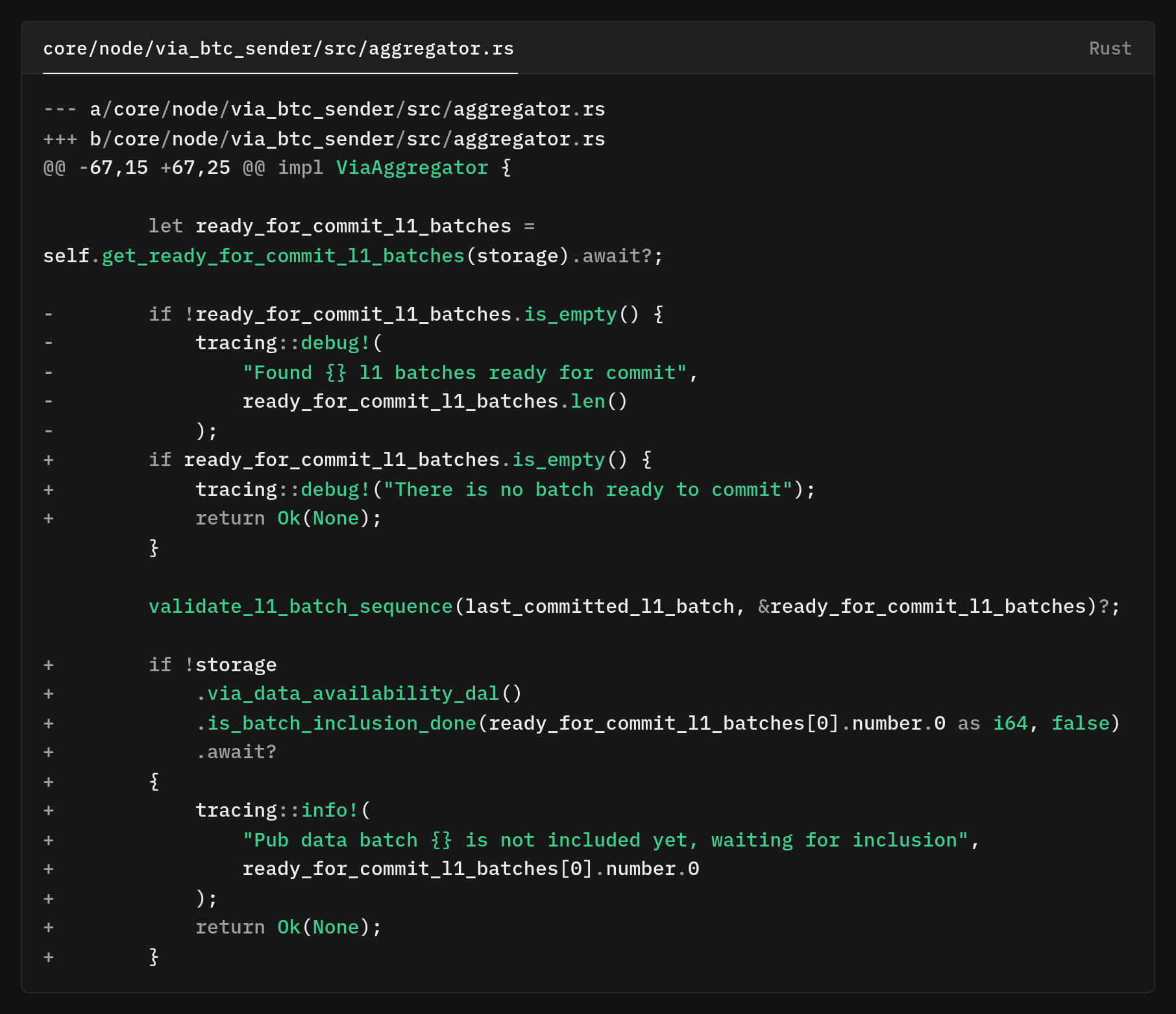
The check happens before extracting the ready subrange.
If the first batch lacks complete inclusion data (all chunks confirmed on Celestia), we return early with Ok(None). This stops the aggregator from creating inscriptions that would fail due to incomplete data.
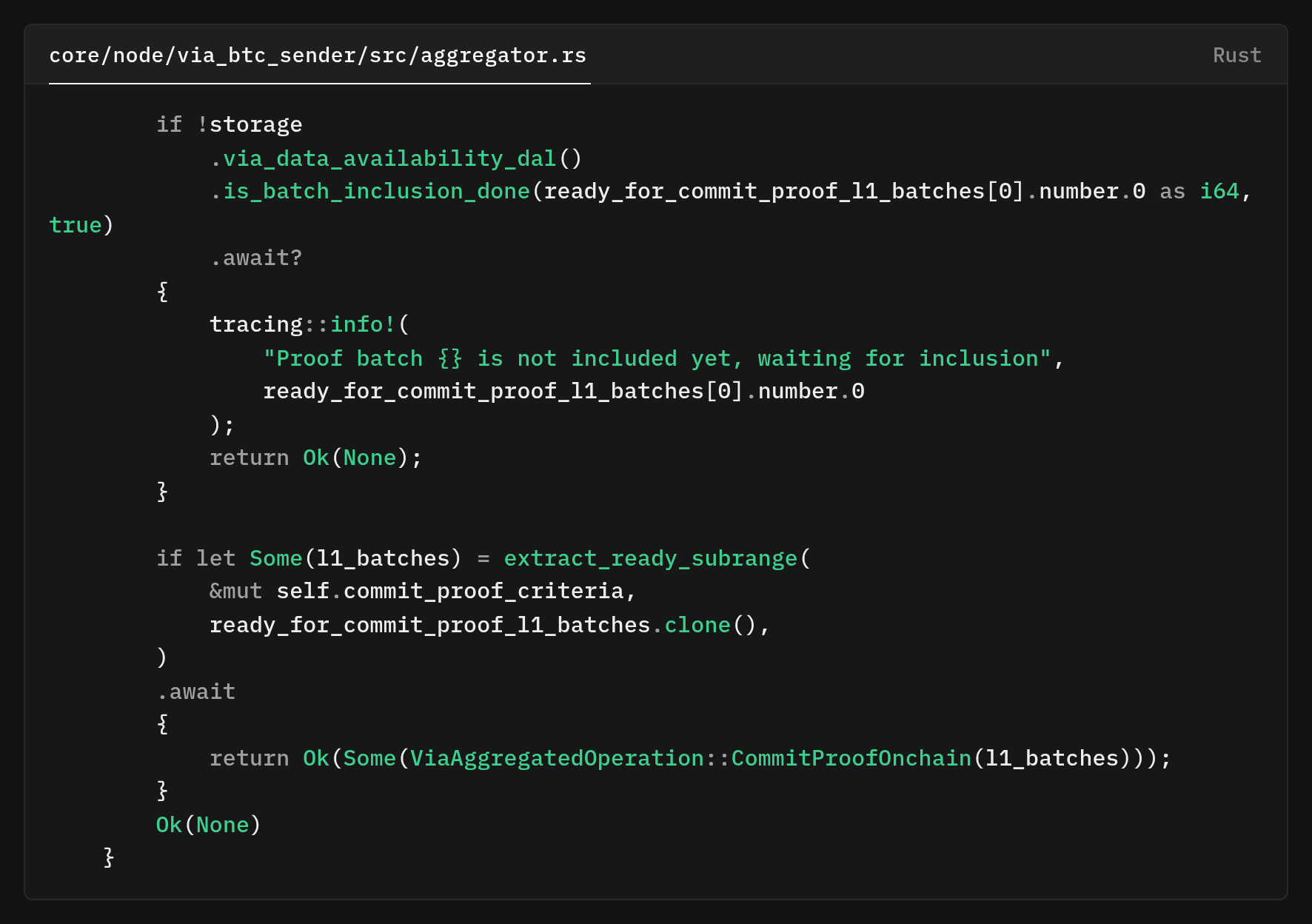
The only difference is the is_proof flag set to true, checking proof blob chunks rather than batch data. Separating batch and proof data via the is_proof column allows independent tracking, which is important as they're generated and posted at different times in the rollup lifecycle.
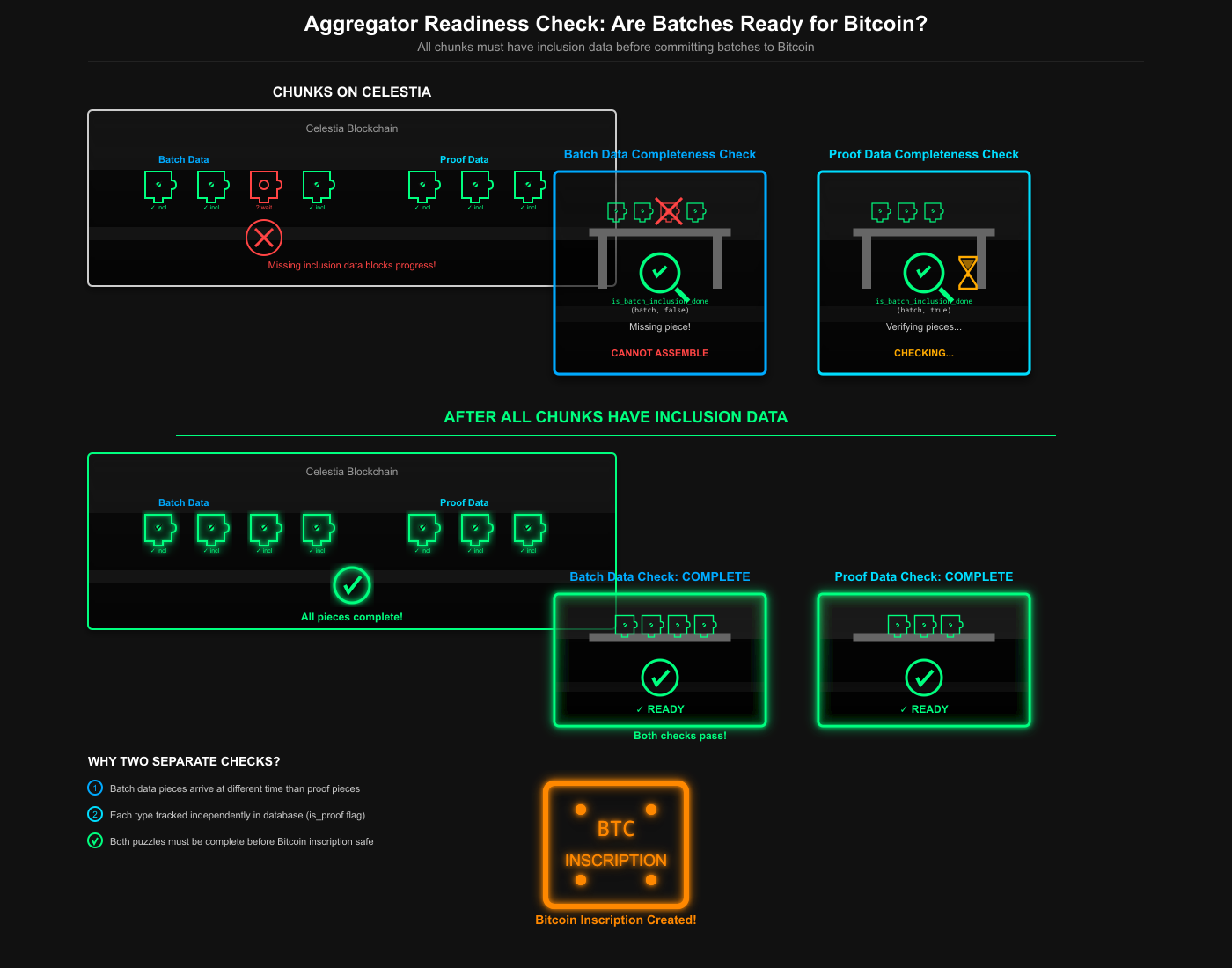
The chunking implementation increases the number of database rows to match the batch size. A 2MB proof that used to have 1 row now has 5 (4 chunks + 1 metadata blob).
The impact on query performance isn't notably reduced because our queries use indexed lookups on the primary key, but it does affect the database size over time. Storage costs are still minimal compared to the value of supporting arbitrarily large batches.
By defaulting the index to 0 for existing rows, we got backward compatibility without data migration scripts. The primary key is handled correctly by dropping and recreating it.
About Via
Via Network is a modular sovereign, validity-proof zk-rollup for Bitcoin with a zkEVM execution layer using Celestia DA that scales throughput without introducing new L1 programmability or custodial trust.
🌐 Website
🧑💻 Testnet Bridge
🐦 (X) Twitter
👋 Discord
🙋♂️ Telegram
📖 Blog
🗞️ Docs
💻 Github