
Verifier Network Upgrade: Faster Deterministic Finality

We've rolled out an upgrade patch for deterministic finality, lower memory, and faster verification for the Via Verifier Network. As we fixed a subtle consensus edge case in our verifier network: duplicate canonical batches
We've introduced partial unique indexes in PostgreSQL to enforce a key rule at the database level
Only one canonical or pending batch can exist per batch number ever
We rewrote batch selection to always pick the last valid L1 batch from the canonical transaction chain.
Deterministic finality: once a batch is finalized, the outcome is unique and reproducible across verifiers.
This change not only eliminated a race condition but also improved performance and ensured verifiers always agree on the same version of history.
- improving query performance by 10-100x: canonical-batch path is now O(n²) → O(n log n).
- Reduced redundant operations
- Lower memory usage
- Performance win:
This is our second post for PR #221. One may wonder why this needs a second post? Spoiler: it needs 3 blog posts.
The scope of improvements in PR221 is too large and too elegant for just a single post.
Each entry in this series of blogs captures architectural changes and fixes. Every improvement reflects how to solve complex problems with surprisingly elegant solutions.
If you aren't familiar with Via yet, read our introduction blog post

Duplicate Batch Constraints
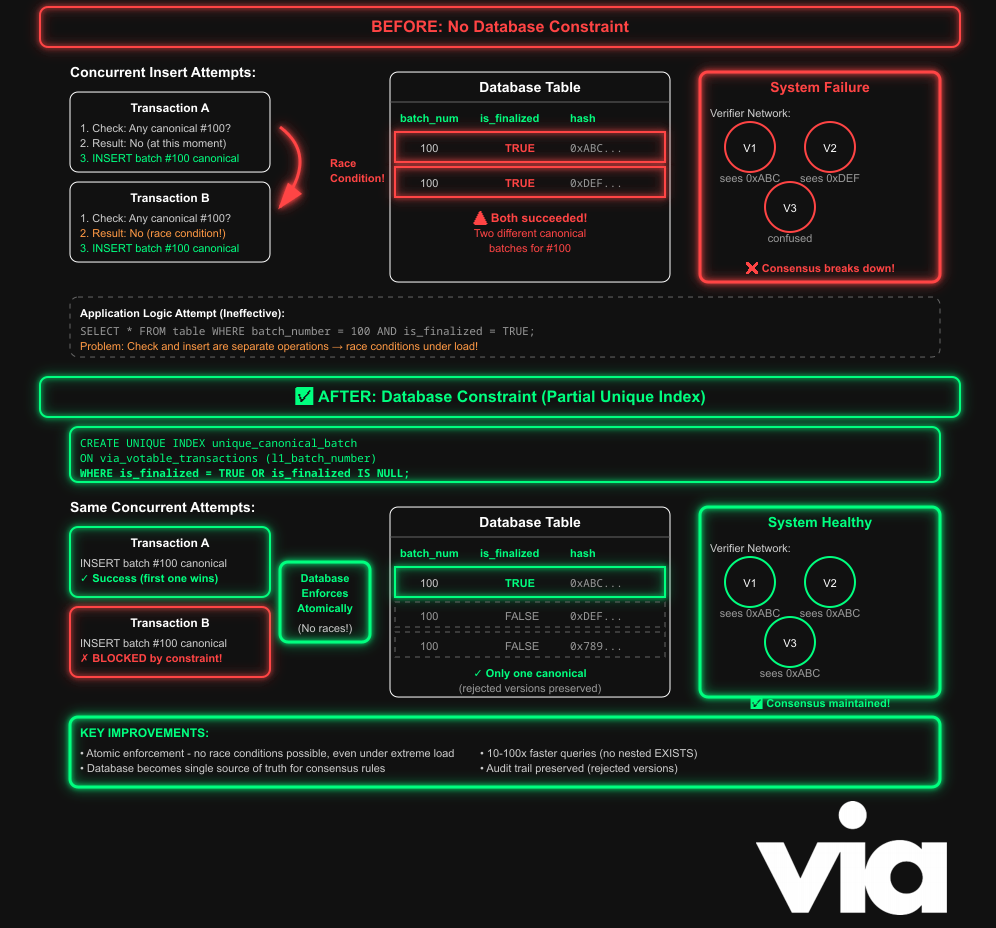
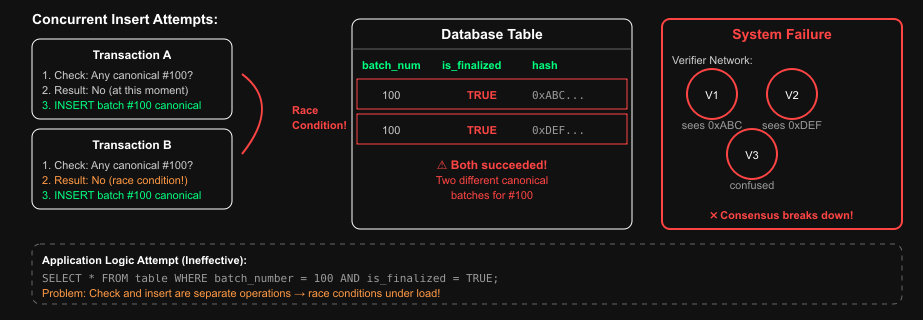
While testing our verifier network, our engineers found an edge case where two different batches shared the same batch number, both of which were flagged as canonical. The database accepted both, creating a state where components disagreed on history. Verifiers voted on divergent timelines.
This is the second post of our larger PR patch 221
After investigating, we found the database may store multiple versions of a batch (e.g., if one is later rejected and re-proposed), but at most one version can ever be canonical. A plain, unique contract on l1_batch_number wouldn't work.
The missing piece: Whilel1_batch_hashwasuniqueWhile it did prevent duplicate hashes, there was nothing stopping multiple different batches with the samel1_batch_numberfrom being marked as canonical.
Which allowed scenarios like this to happen
| l1_batch_number | is_finalized | l1_batch_hash | Problem |
|-----------------|--------------|---------------|---------------------------|
| 100 | TRUE | 0xABC... | ← Canonical batch |
| 100 | TRUE | 0xDEF... | ← DIFFERENT hash |
| 100 | NULL | 0x123... | ← Another pending version |
| 100 | FALSE | 0x456... | ← Rejected (OK to have) | Each row has a unique l1_batch_hash satisfying that constraint, but nothing prevented two completely different batches (with different hashes, meaning different contents) could sharing the same l1_batch_number, and both be marked as canonical (is_finalized = TRUE).
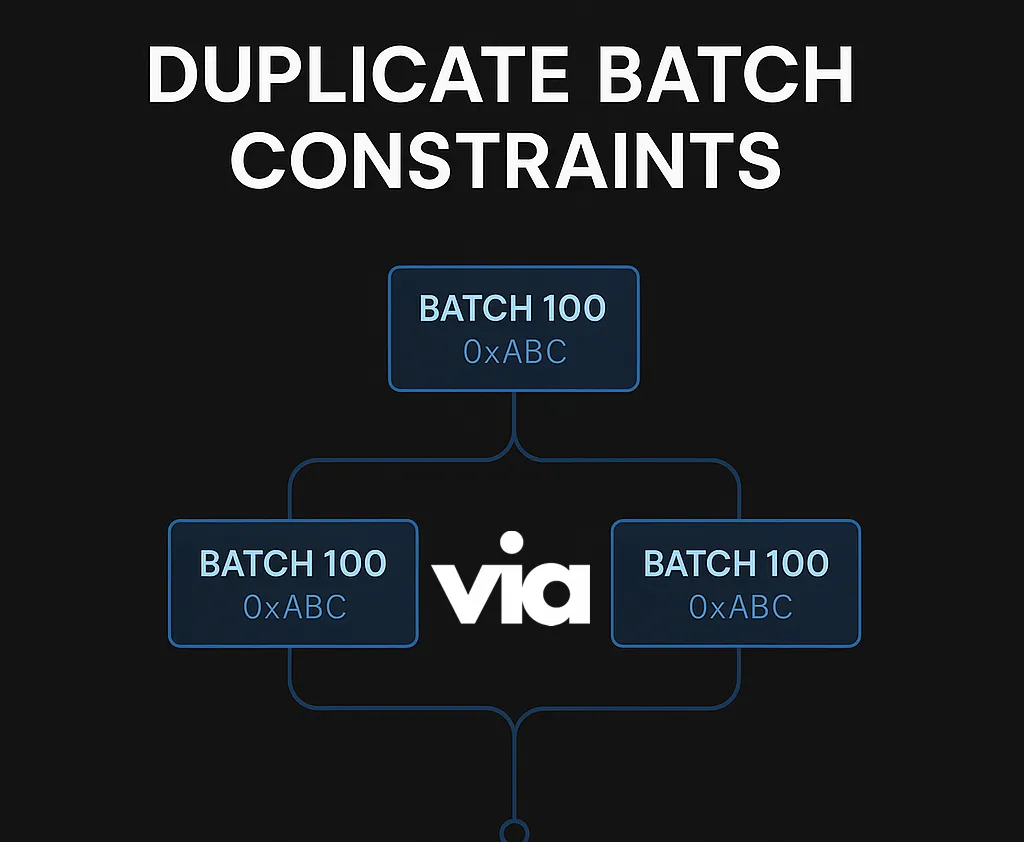
The verifier network couldn't agree on which version of the batch was canonical, because multiple conflicting versions existed and were considered valid.
Our old approach to preventing this was prone to a race condition with a nested query
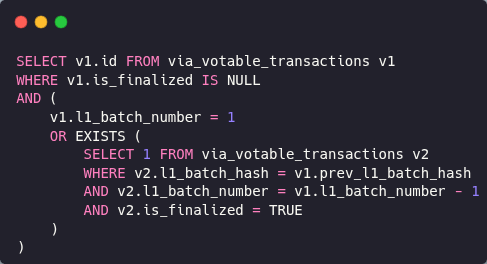
This nested EXIST approach has its flaws
For one, it was vulnerable to race conditions where there was a window between checking for an existing canonical batch and actually inserting a new one, during which another transaction could slip in a conflicting insert.
Second, the nested subquery ran for every row, resulting in O(n²) time complexity, a bottleneck.
Solution: PostgreSQL's partial indexes
The solution: PostgreSQL's partial indexes allow enforcing uniqueness only for rows that are canonical (or pending), while allowing rejected versions to coexist.
A PostgreSQL partial unique index is a special kind of index that enforces uniqueness but only for rows that match a certain condition. The condition is defined in the WHERE clause of the index. This makes it different from a regular unique index, which applies to all rows in a table.
In our case, when working with batches of data that can be in different states, some are canonical (finalized and accepted), some are pending (still being considered), and some are rejected. These states are represented using a column like is_finalized which can be TRUE for canonical, NULL for pending and FALSE for rejected.
There's an important rule we wanted to enforce. There can only ever be one canonical or pending batch per batch number.
We want to prevent a situation where, for example, two different batches are both marked as canonical for batch number 100 (as an example). Otherwise, this would cause issues in the verifier network consensus system because different parts of the verifier network could believe different things are the "real" chain.
At the time, we want to allow multiple rejected versions of a batch to be stored in the database, as it could be useful for debugging or any future analysis. So we wouldn't just make l1_batch_number globally unique across the table because that would block us from saving rejected versions.

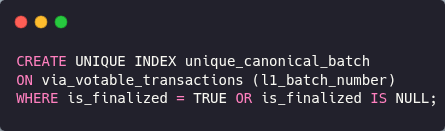
This is where a partial unique index comes in, where we create an index that enforces uniqueness on l1_batch_number , but only for rows where is_finalized is TRUE or NULL. In other words, we only want to enforce uniqueness when a batch is canonical or pending. If a batch is rejected (i.e. is_finalized = FALSE). The uniqueness rule doesn't apply, and multiple rejected rows with the same batch number are allowed.
Only one canonical or pending batch is allowed per batch number, but any number of rejected versions is fine.
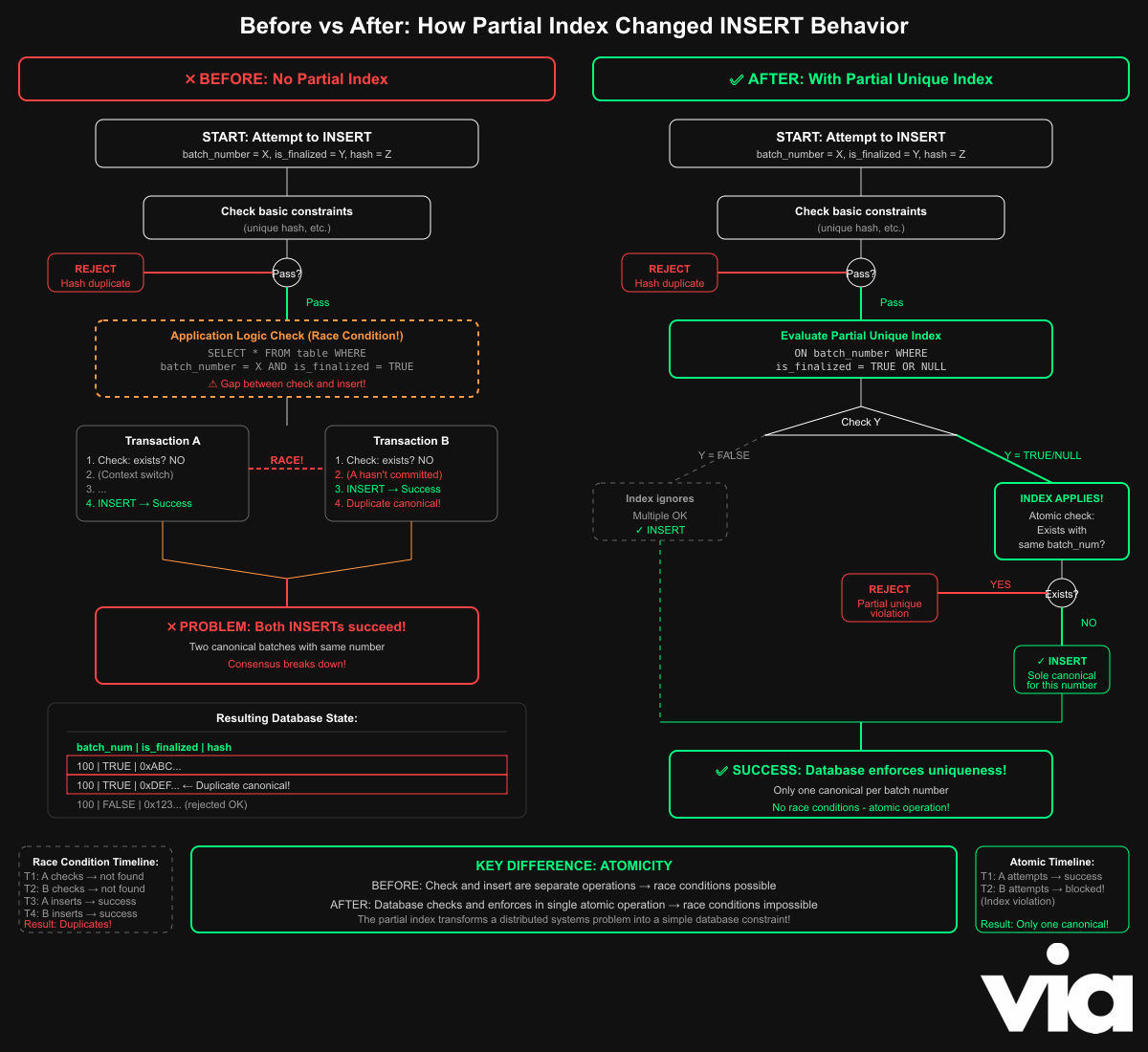
This rule is enforced atomically during inserts, meaning even under heavy concurrency, the database will never allow two conflicting rows to slip through. It completely eliminates the need to scan with extra code for duplicates or handle race conditions, as now PostgreSQL itself guarantees consistency.
As a result, our database schema now directly encodes an important consensus rule, which is that only one active candidate per batch number can exist.
So, a solution came in the form of a new database migration that introduced a partial unique index to enforce consensus integrity at the database level.
The WHERE clause defines a filtered index, meaning only rows where is_finalized is TRUE (canonical) or NULL (pending) are index.
Rejected batches (is_finalized = FALSE) are excluded entirely from the index and can safely coexist.
Within this indexed subset, PostgreSQL enforces uniqueness on l1_batch_number to guarantee that only one canonical or pending batch can exist.
The index constraint is enforced atomically, which means during the same transaction as the insert, getting rid of race conditions entirely.
The elegance here is in how the database-level constraint complements application logic. Enforcing uniqueness via a partial index while also replacing the inefficient nested EXIST queues with Common Table Expressions, which not only improved query clarity but also
- Reduced redundant operations
- Lower memory usage
What was once a source of bugs is now impossible by design as the database becomes the source of truth for integrity. Using PostgreSQL’s partial index feature, applying just enough precision to enforce correctness without over-constraining the system.
Start: Attempt to INSERT new row with l1_batch_number = X, is_finalized = Y, l1_batch_hash = Z
|
v
Check existing constraints (e.g., unique l1_batch_hash)
|
+-- If violates (e.g., hash duplicate) --> REJECT INSERT (Error: Unique violation)
|
v
Evaluate Partial Unique Index (on l1_batch_number WHERE is_finalized = TRUE OR NULL)
|
+-- If Y = FALSE (Rejected) --> Index ignores this row --> ALLOW INSERT
| (Multiples OK; coexist with others)
|
+-- If Y = TRUE (Canonical) or Y = NULL (Pending):
| |
| v
| Check if another row with l1_batch_number = X and (TRUE or NULL) exists
| |
| +-- If YES --> REJECT INSERT (Error: Partial unique violation)
| | (Prevents duplicate canonical/pending)
| |
| +-- If NO --> ALLOW INSERT
| (Becomes the sole canonical/pending for this number)
|
v
End: Row inserted (or rejected). Canonical chain remains unique; rejected versions accumulate freely.
By pushing the "one active candidate per number" rule into the database, we made it impossible by design for the verifier to disagree about history. The logic selects the latest valid canonical, the schema forbids competing canonicals/pending rows, and the planner keeps the path fast.
Special thanks to Idir TxFusion for being the co-author and original author of patch 221
Code snippets
We showed the code in an image format. Here are the code snippets that you can copy and paste to experiment.
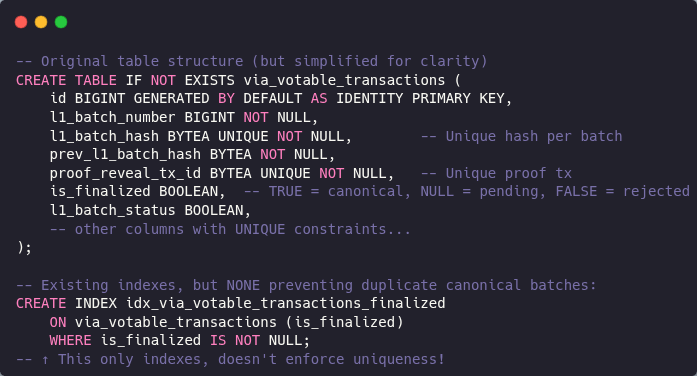
Prior to this fix, the via_votable_transactions table (from migration 20250112053854_create_via_votes.up.sql) had several unique constraints, but none that prevented duplicate canonical batches:
Original table structure (simplified)
-- Original table structure (simplified for clarity)
CREATE TABLE IF NOT EXISTS via_votable_transactions (
id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
l1_batch_number BIGINT NOT NULL,
l1_batch_hash BYTEA UNIQUE NOT NULL, -- Unique hash per batch
prev_l1_batch_hash BYTEA NOT NULL,
proof_reveal_tx_id BYTEA UNIQUE NOT NULL, -- Unique proof tx
is_finalized BOOLEAN, -- TRUE = canonical, NULL = pending, FALSE = rejected
l1_batch_status BOOLEAN,
-- other columns with UNIQUE constraints...
);
-- Existing indexes, but NONE preventing duplicate canonical batches:
CREATE INDEX idx_via_votable_transactions_finalized
ON via_votable_transactions (is_finalized)
WHERE is_finalized IS NOT NULL;
-- ↑ This only indexes, doesn't enforce uniqueness!
While l1_batch_hash was unique (preventing duplicate hashes), there was no constraint preventing multiple different batches with the same l1_batch_number from being marked canonical.
Which allowed scenarios like this to happen:
| l1_batch_number | is_finalized | l1_batch_hash | Problem |
|-----------------|--------------|---------------|------------------------------|
| 100 | TRUE | 0xABC... | ← Canonical batch |
| 100 | TRUE | 0xDEF... | ← DIFFERENT hash, same number|
| 100 | NULL | 0x123... | ← Another pending version |
| 100 | FALSE | 0x456... | ← Rejected (OK to have) |
Each row has a unique l1_batch_hash, satisfying that constraint, but nothing prevented multiple rows with l1_batch_number = 100 and is_finalized = TRUE.
Our old approach to preventing this was prone to a race condition with a nested query
// Old inefficient query with race condition vulnerability
SELECT v1.id FROM via_votable_transactions v1
WHERE v1.is_finalized IS NULL
AND (
v1.l1_batch_number = 1
OR EXISTS (
SELECT 1 FROM via_votable_transactions v2
WHERE v2.l1_batch_hash = v1.prev_l1_batch_hash
AND v2.l1_batch_number = v1.l1_batch_number - 1
AND v2.is_finalized = TRUE
)
)
This nested EXISTS approach had two flaws:
- Race conditions: Between checking and inserting, another transaction could slip in
- O(n²) performance: The nested subquery ran for every row, causing exponential slowdown
The fix: Database-enforced uniqueness
The solution came in the form of a new database migration that adds a partial unique index:
New Migration (20250730193407_fix_votable_transaction.up.sql):
-- Allow duplicate batch numbers, but only one can be in canonical chain
CREATE UNIQUE INDEX unique_canonical_batch
ON via_votable_transactions (l1_batch_number)
WHERE is_finalized = TRUE OR is_finalized IS NULL;


