
Verifier Network upgrade: State-aware validation & deterministic head selection

We've rolled out yet another major upgrade to the Via Verifier Network, which makes chain progression more reliable under load while reducing network overhead by half during batch ingestion.
The upgrade also strengthens chain integrity and closes a subtle TOCTOU window, which makes head selection deterministic.
TL;DR
- ~50% reduction in RPC calls during batch ingestion by eliminating a redundant indexer lookup and dual parsing path
- Deterministic head selection: a forward walk from the last finalized batch using a recursive SQL CTE yields a single canonical head.
- , which makes chain progression more reliable under load while reducing network overhead by
- One‑pass parsing: Parse the reveal transaction once. Derive the batch number from the same parsed payload.
- TOCTOU window closed: removed the pre‑check that introduced a timing gap; no more silent drops from transient RPC/parse hiccups.
- Outcome: smoother consensus, fewer stalls, cleaner failures, and less network overhead at peak.
50% reduction in RPC calls, specifically during batch ingestion. We worked around to avoid an extra indexer lookup and dual parsing path.
By getting the batch number directly from the reveal transaction payload, the verifier now makes only one round-trip per batch. This reduces network overhead by half during peak submission times.
Deterministic head selection, by walking forward through valid, non-rejected successors from the last finalized batch, the verifier reliably resolves the canonical head
Improved state-aware batch validation, Via Verifier Message processor now performs state-aware validation to prevent forked, duplicate, or improperly ordered batches from entering the canonical chain
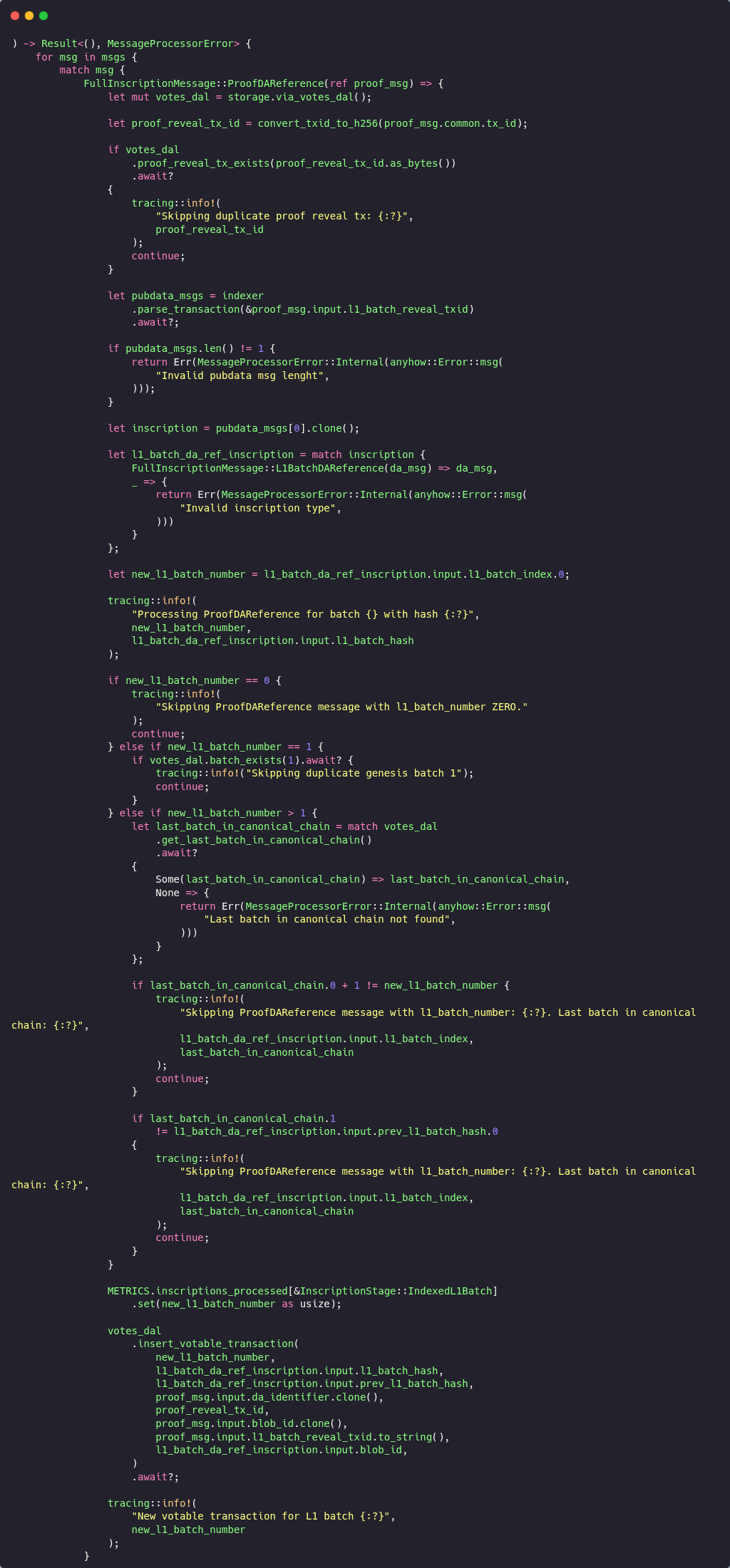
Fixing the Time-of-Check to Time-of-Use race condition challenge
Batches were expected to arrive, and rejected batches were assumed to be cleaned up immediately. The genesis batch was handled by separate init logic.
Networks don't always behave that neatly as expected. Batches can show up out of order. Rejected ones must be retained for auditability.
In an ideal world, batches would arrive one after the other, perfectly ordered. In practice, especially in distributed systems, batches can arrive out of order due to network latency, propagation delays, or processing jitters across the nodes or network.
Our original code made assumptions about network behavior and batch ordering, while our newly improved implementation enforces strict validation at the entry point.
The verifier network process batches that must maintain structured ordering and cryptographic integrity. Each batch has
- A sequential batch number
- A hash identifying the batch
- A previous batch hash linking to its parent
- Transaction data and proofs
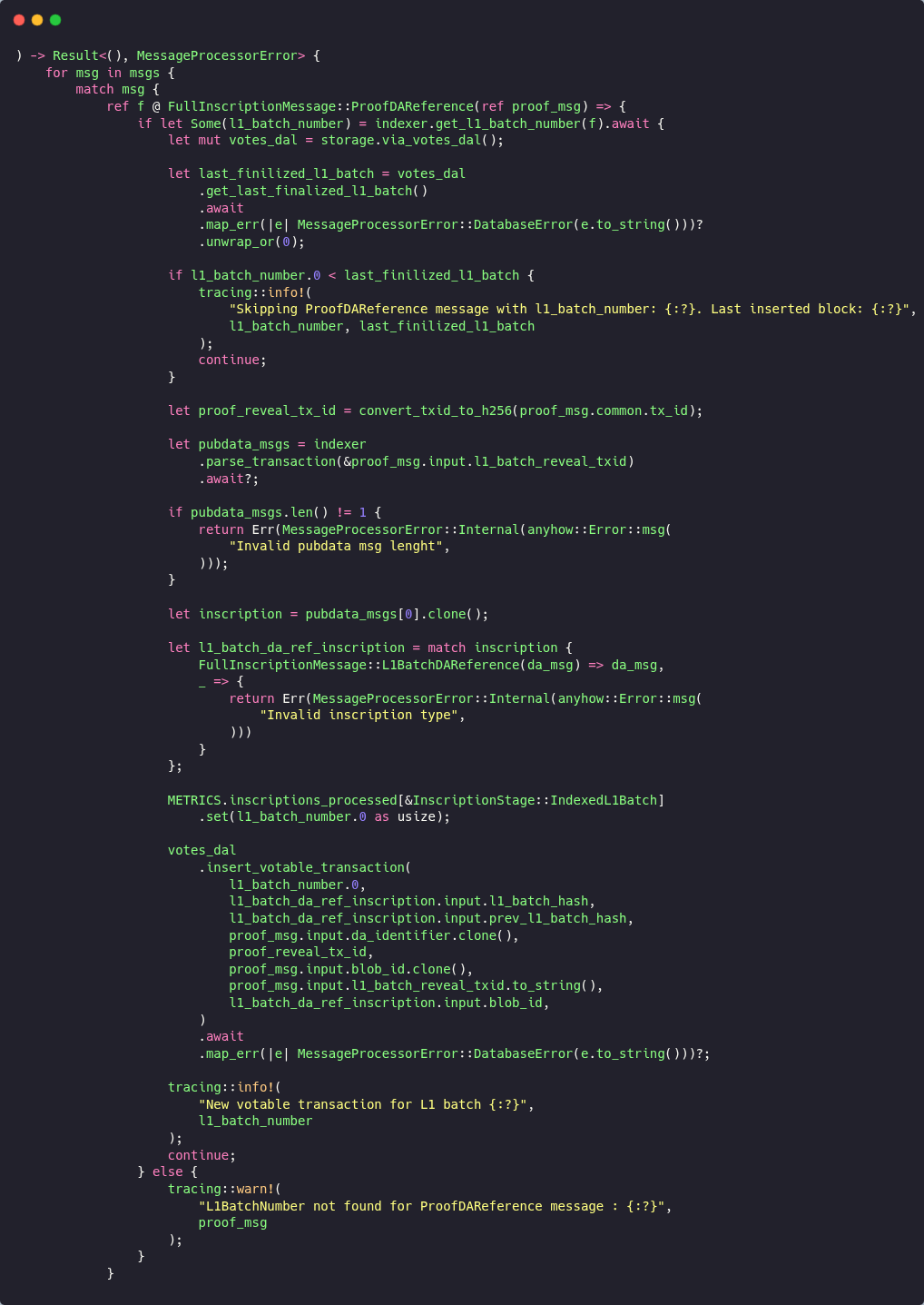
Race condition with get_l1_batch_number
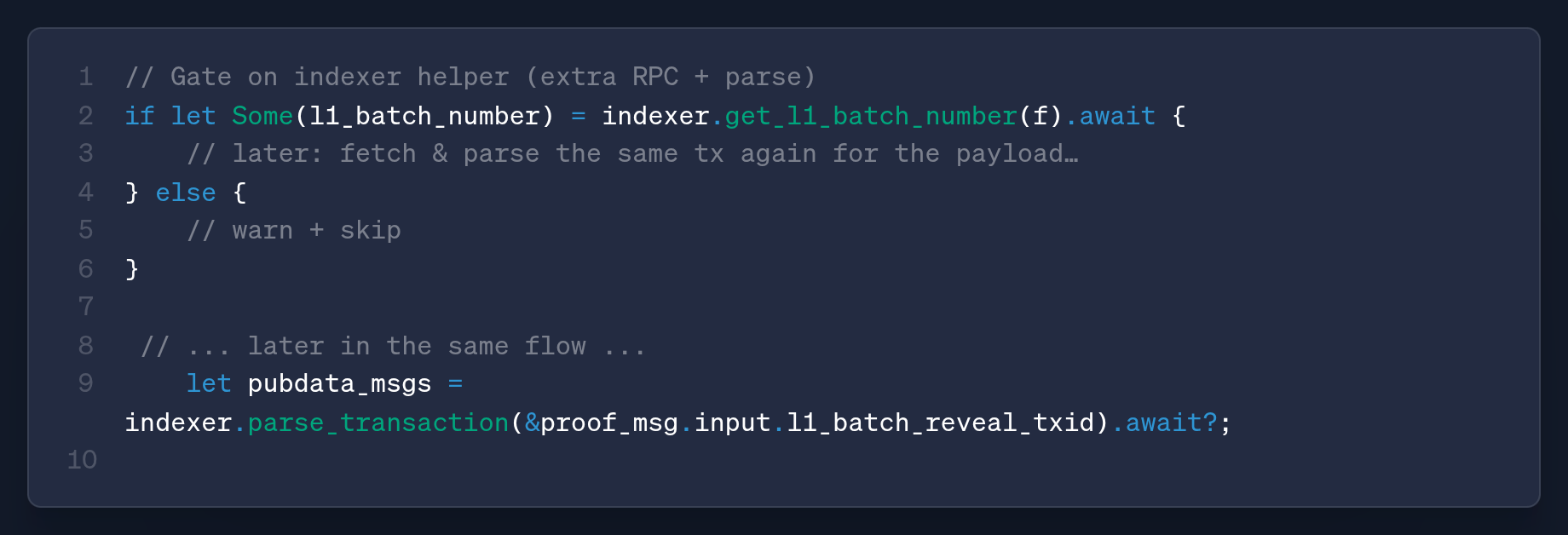
The original verifier code pulled the batch number by calling the indexer rather than reading it directly from the message payload that was already in hand. You can see this where the processor gated its logic behind f let Some(l1_batch_number) = indexer.get_l1_batch_number(f).await {.
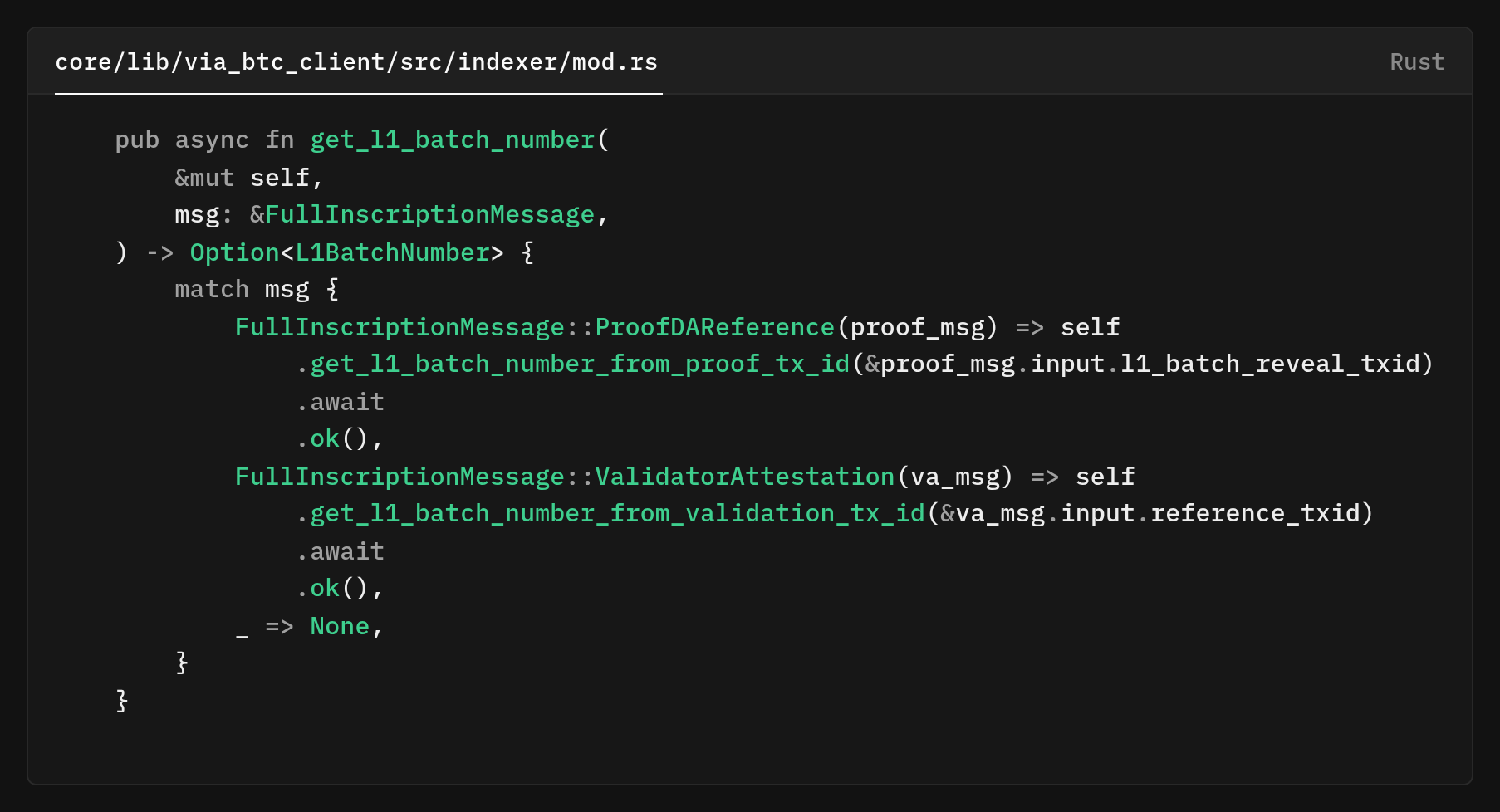
get_l1_batch_number https://github.com/vianetwork/via-core/blob/main/core/lib/via_btc_client/src/indexer/mod.rs#L263That helper get_l1_batch_number does not read from a separate cache or mapping. It makes a fresh Bitcoin RPC call to fetch the reference transaction and then parses it to recover the batch index via get_l1_batch_number_from_proof_tx_id which itself runs the parser over the transaction.
After that, the main verifier patch also fetched and parsed the same transaction again through parse_transaction(), so the batch number was effectively recovered by a separate RPC and flow before the code continued to parse the payload once more for the actual inscription data.
Now, because the batch number was gated by an extra network-dependent round-trip, a timing gap was created between two independent fetch-and-parse operations.
If the indexer's RPC couldn't retrieve or parse the reveal transaction at the moment, get_l1_batch_number() it returned None The caller simply warned and skipped the process.
That “drop-on-None” behavior meant silent failures, as messages could be missed.. The helper also relied on taking the .first parsed message from a transaction and asserting the expected type
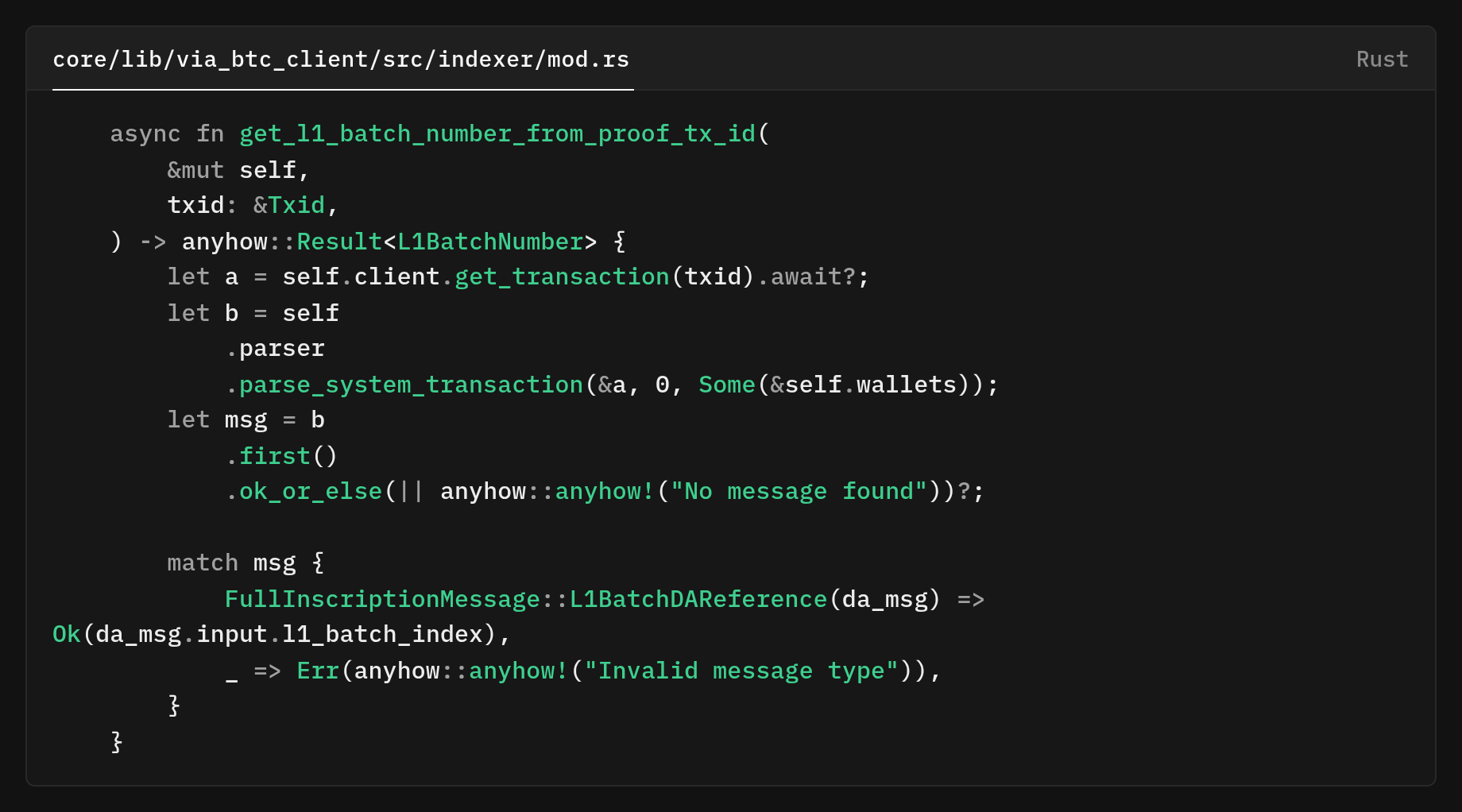
.first https://github.com/vianetwork/via-core/blob/main/core/lib/via_btc_client/src/indexer/mod.rs#L406In situations where transactions included multiple relevant inscriptions or the order was different, this assumption could break down and produce a false None result even if the payload contained this data.
Altogether, this created a time-of-check/time-of-use race where one code path decided whether the message was processable based on a separate async parse result, and a later path parsed again for the actual content.
So what was happening?
The verifier asked an indexer helper for the batch number. The helper made a new Bitcoin RPC call and parsed the transaction to recover the index. Later, in the same verifier process, the code fetched and parsed that same transaction again to read the actual DA-reference payload.
Why is that bad?
It created a time-of-check/time-of-use (TOCTOU) window between two independent "fetch and parse" steps. If the first RPC/parse can't see or can't parse the reveal tx yet, the helper returns None and the verifier skips the message (warns but continues).
The helper didn’t consult a different authority, so it wasn’t semantically contradicting the payload. The inconsistencies were timing/assumption induced
We removed the indexer gate and ref f @ binding to drop the extra RPC + parse and TOCTOU race, as we no longer “pre-check” and process the message we already have.
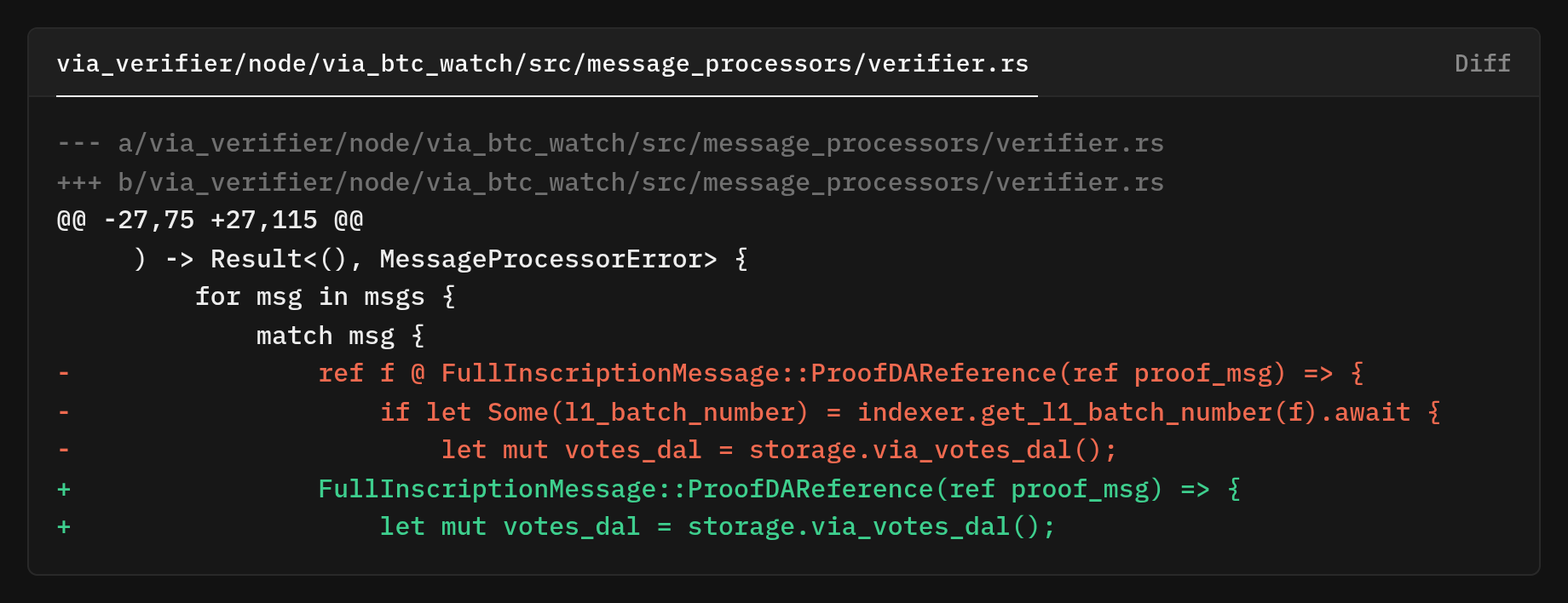
The first thing the new branch does is compute the reveal transaction ID from the message itself
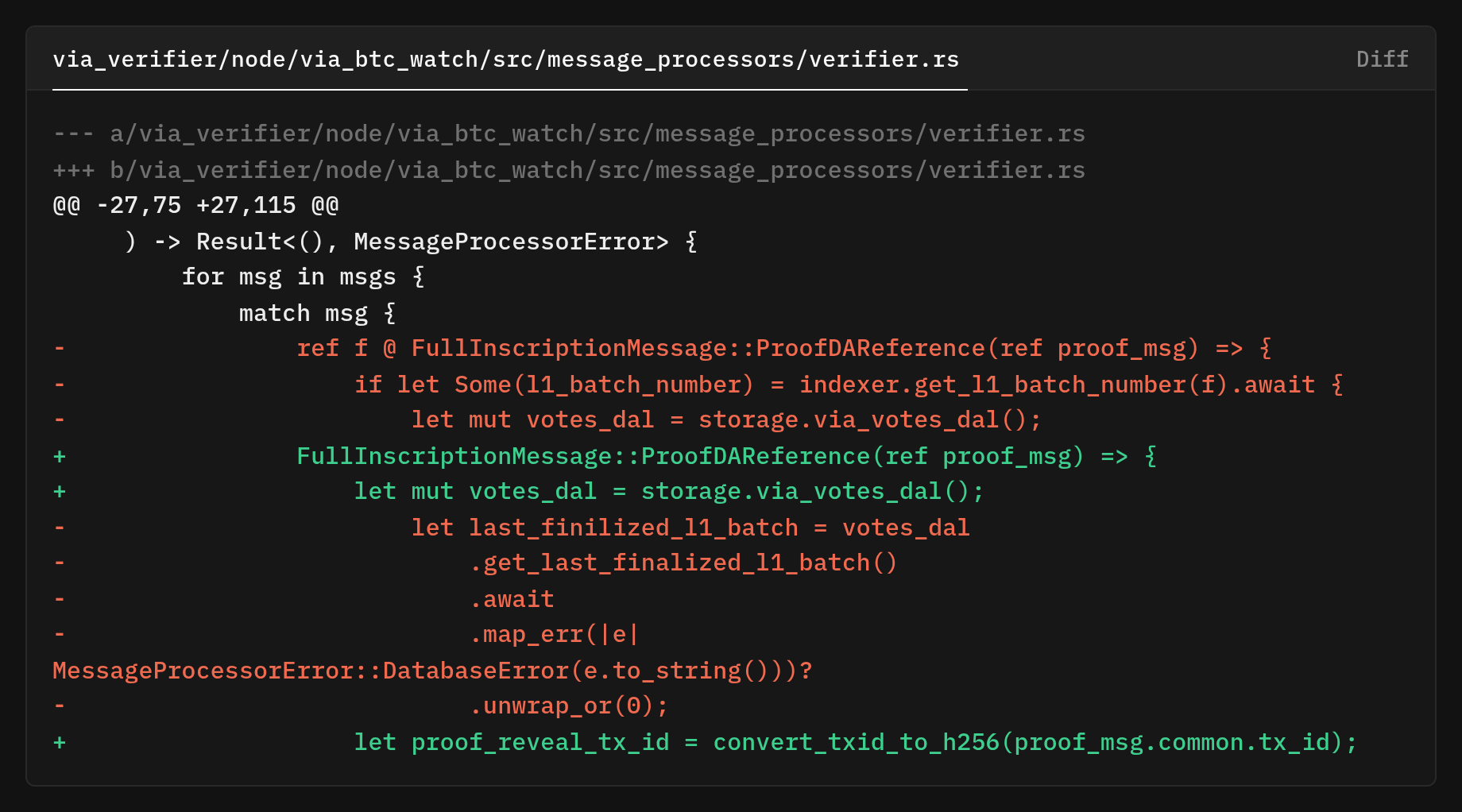
and then perform a duplicate‑reveal guard in the database so replays don’t get processed twice
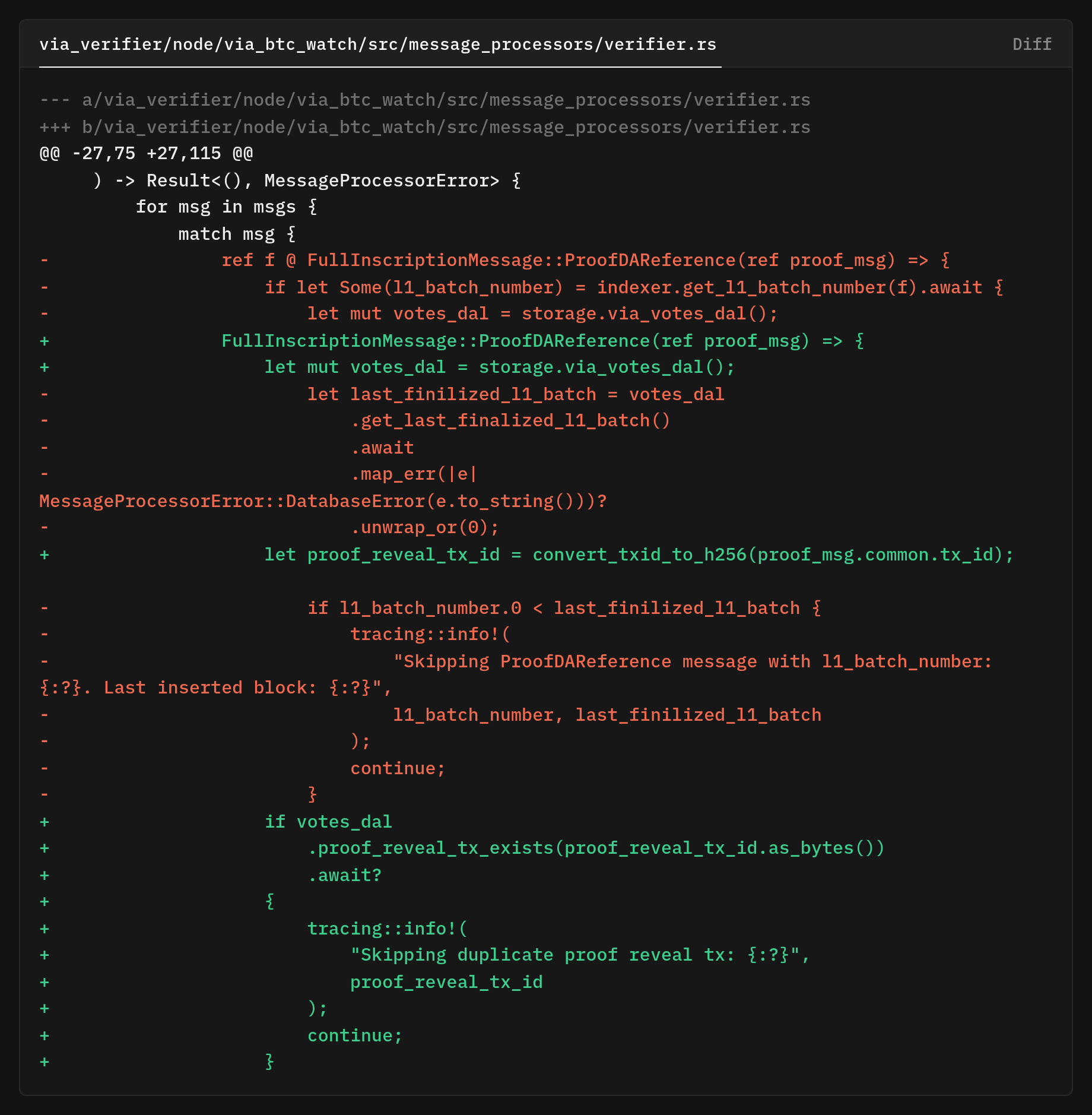
Only then does it perform the one necessary network call and parse the reveal transaction via indexer.parse_transaction(&proof_msg.input.l1_batch_reveal_txid, which is the single source of parsed payload for the rest of this control flow (the method itself is defined at .parse_transaction()
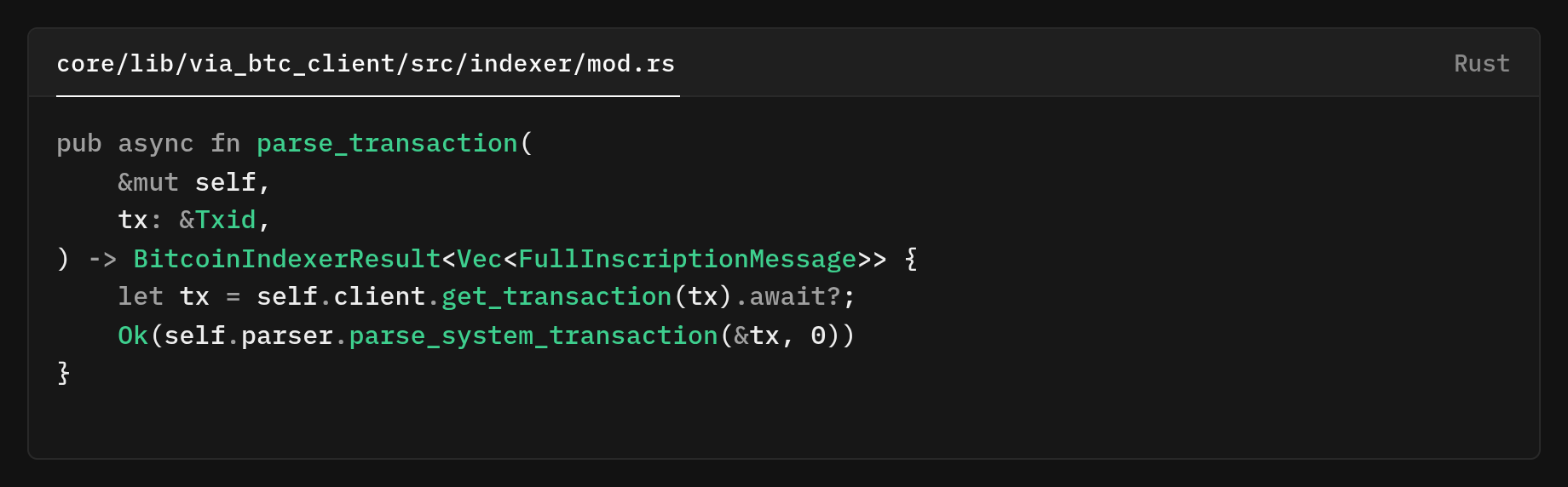
This fetches the tx from the Bitcoin node, and it's a one-round-trip to get the raw transaction by its Txid. The self.parser.parse_system_transaction(&tx, 0) runs the parser once and returns a vector of FullInscriptionMessage value found in that transaction. The 0 is a parser context/flag value.
From that single parsed payload, the verifier expects exactly one VIA message; if there’s anything else (zero or multiple), it returns an error and stops.
It then asserts that the message is the expected L1BatchDAReference and, once confirmed, derives the batch number directly from the parsed payload
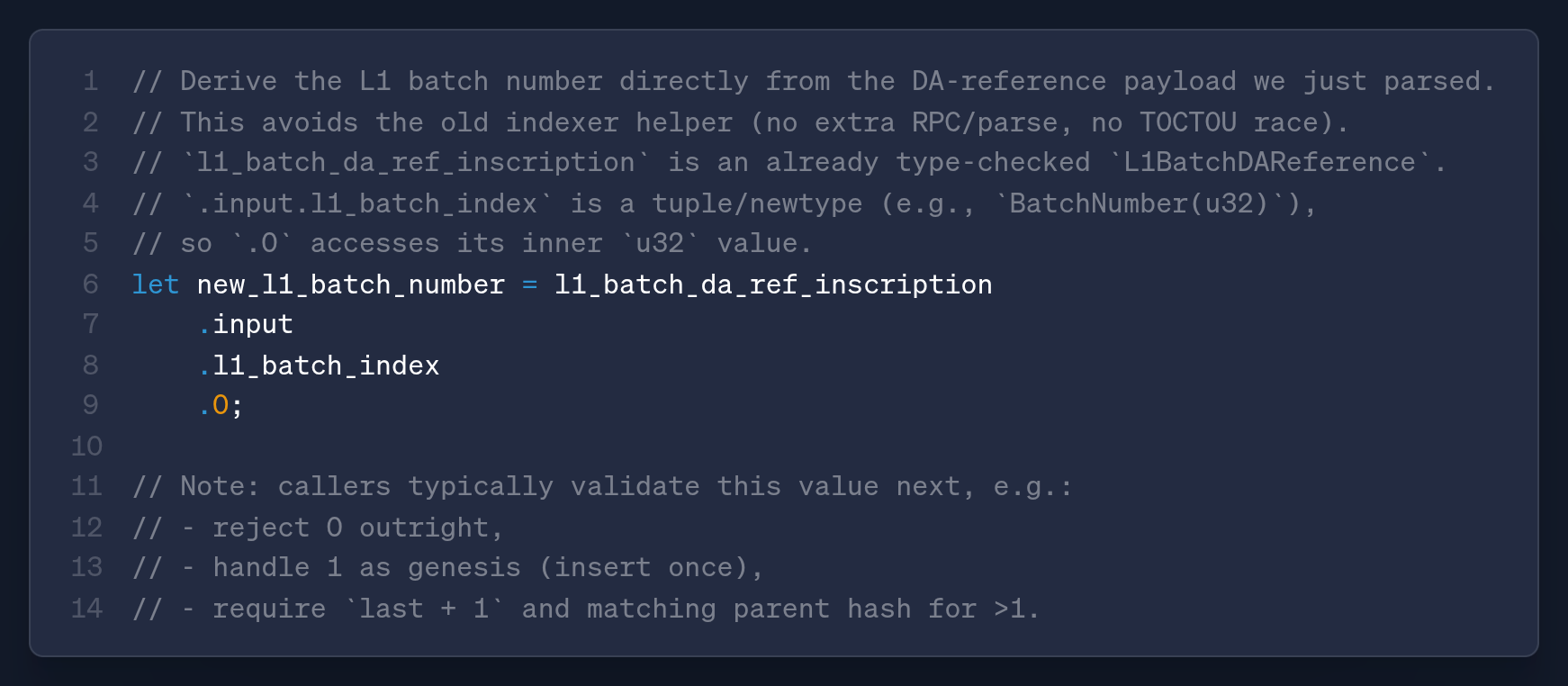
With the number in hand, the code applies simple integrity rules for practical edge cases
- ignoring zero batch numbers
- Treating batch 1 as a special case, skipping it if present in the database, and for higher batches
ensuring chain continuity by requiring the new batch to be the exact successor of the current canonical tip with a matching parent hash.
In other words, the “all the stuff before" serves as the robustness scaffolding for the new pipeline
Deduplication using reveal-tx ID, a single RPC/parse to retrieve the DA-reference, strict shape validation, and then extracting the batch number from the same parsed payload.

The new verifier code part removes these failures by deriving the batch number directly from the DA-reference already parsed in the same control flow.
Instead of calling the indexer first, it now reads l1_batch_da_ref_inscription.input.l1_batch_index.0 from the parsed inscription, removing the extra RPC/parse.
That collapses the time-of-check/time-of-use window, preventing the silent drops from transient RPC/parsing hiccups with a single source of truth. The payload is being validated.
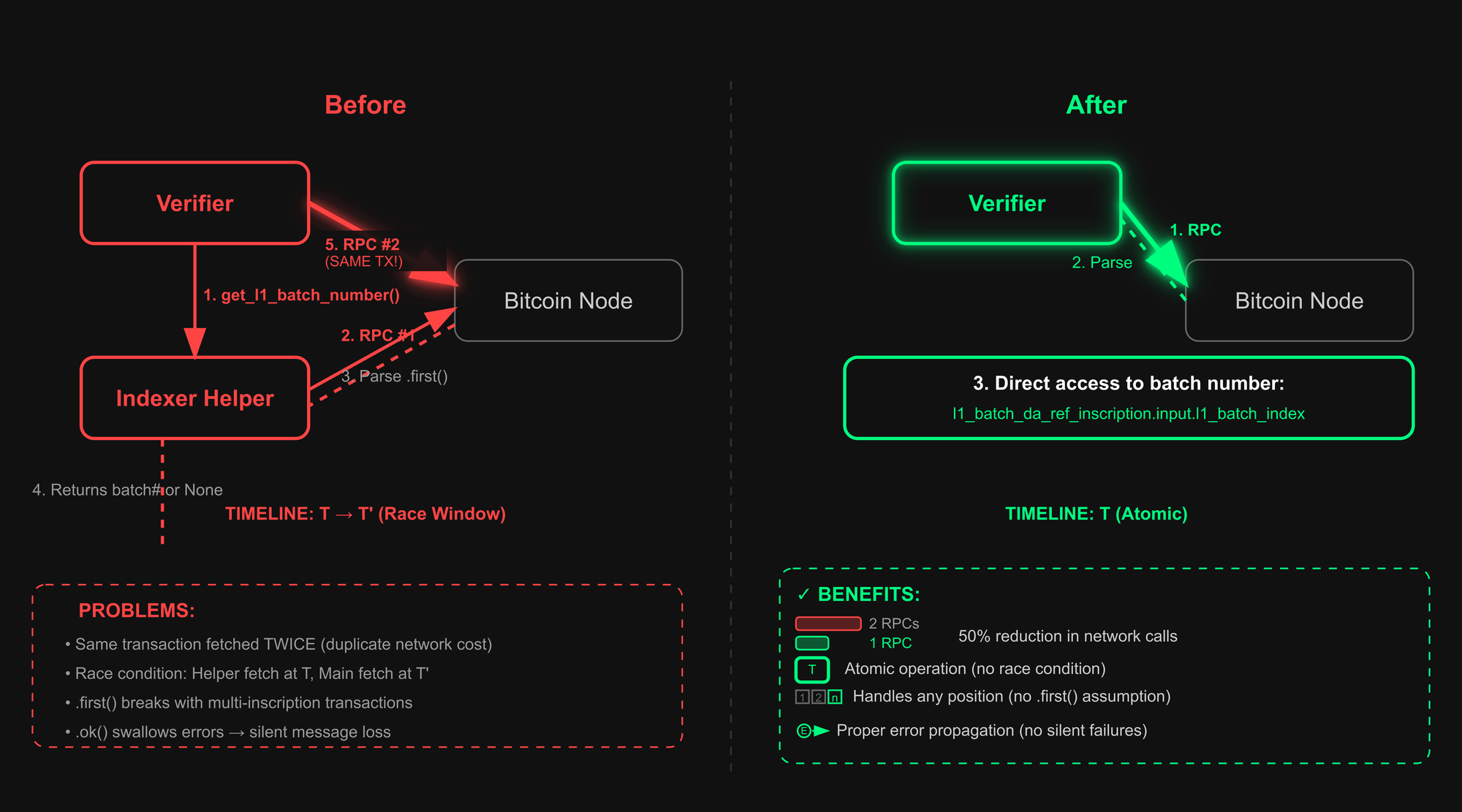
- Single RPC call (50% reduction in network calls)
- Direct access to the batch number from the already-parsed data structure (parse once)
- No race window and proper error propagation
State-Aware Batch Validation
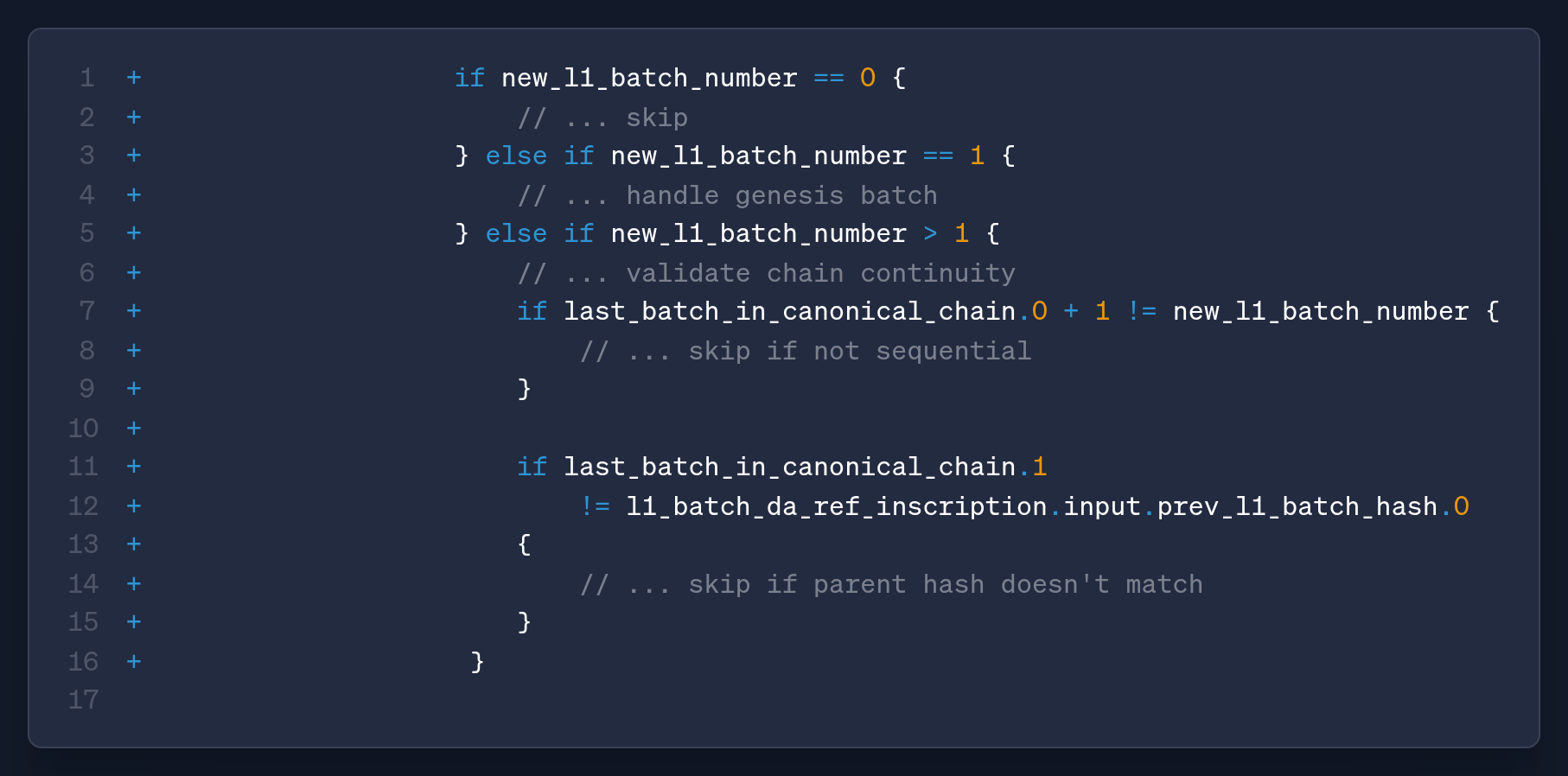
We implemented a new, improved batch validation logic for the verifier network, replacing the simple "is it older than finalized" check.
It understands that different batches have different rules and must be validated based on the current state of the canonical chain.
- Handling Batch 0: It explicitly rejects batch 0, which is an invalid state.
- Genesis Batch (Batch 1): It implements special logic for the first batch, primarily checking for duplicates since it has no parent to link to.
- Sequential Batches (>1): For all subsequent batches, it enforces two critical rules for maintaining chain integrity:
- Strict Sequential Ordering: It fetches the latest batch from the canonical chain (
get_last_batch_in_canonical_chain) and ensures the new batch's number is exactly one greater than the previous one. This prevents out-of-order processing and forks. - Cryptographic Linking: It verifies that the
prev_l1_batch_hashfield in the new batch's payload correctly matches the hash of the previous batch in the chain. Basically, it guarantees that the new batch is cryptographically linked to its parent, ensuring the chain is unbroken.
- Strict Sequential Ordering: It fetches the latest batch from the canonical chain (
We made several changes in our verifier. It now proactively rejects duplicates, validates payload structure, and enforces strict chain integrity rules based on the current state, preventing the class of bugs that caused the original incident.
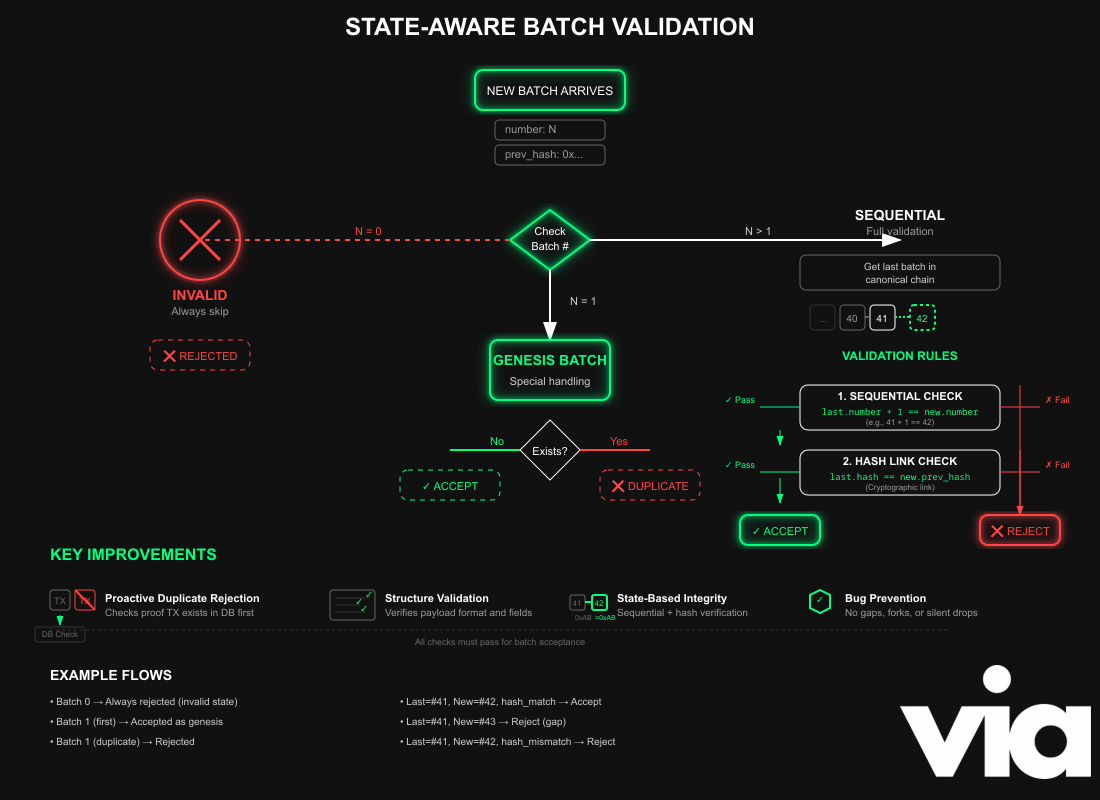
Recursive SQL CTE query
In our verifier network pipeline, we need a fast and deterministic way to determine “where the chain really is” before accepting a new batch.
A naïve “take the largest batch number” is wrong in the presence of rejected or non-canonical batches.
A naive approach would lead to problems:
- When a batch fails validation, it creates a gap in the numbering sequence
- During network issues, chain reorgs, multiple chains might exist temporarily
- Parallel batch submissions can create branches that need to be resolved
We worked on a database helper that computes the true head of the canonical chain using a single SQL query.
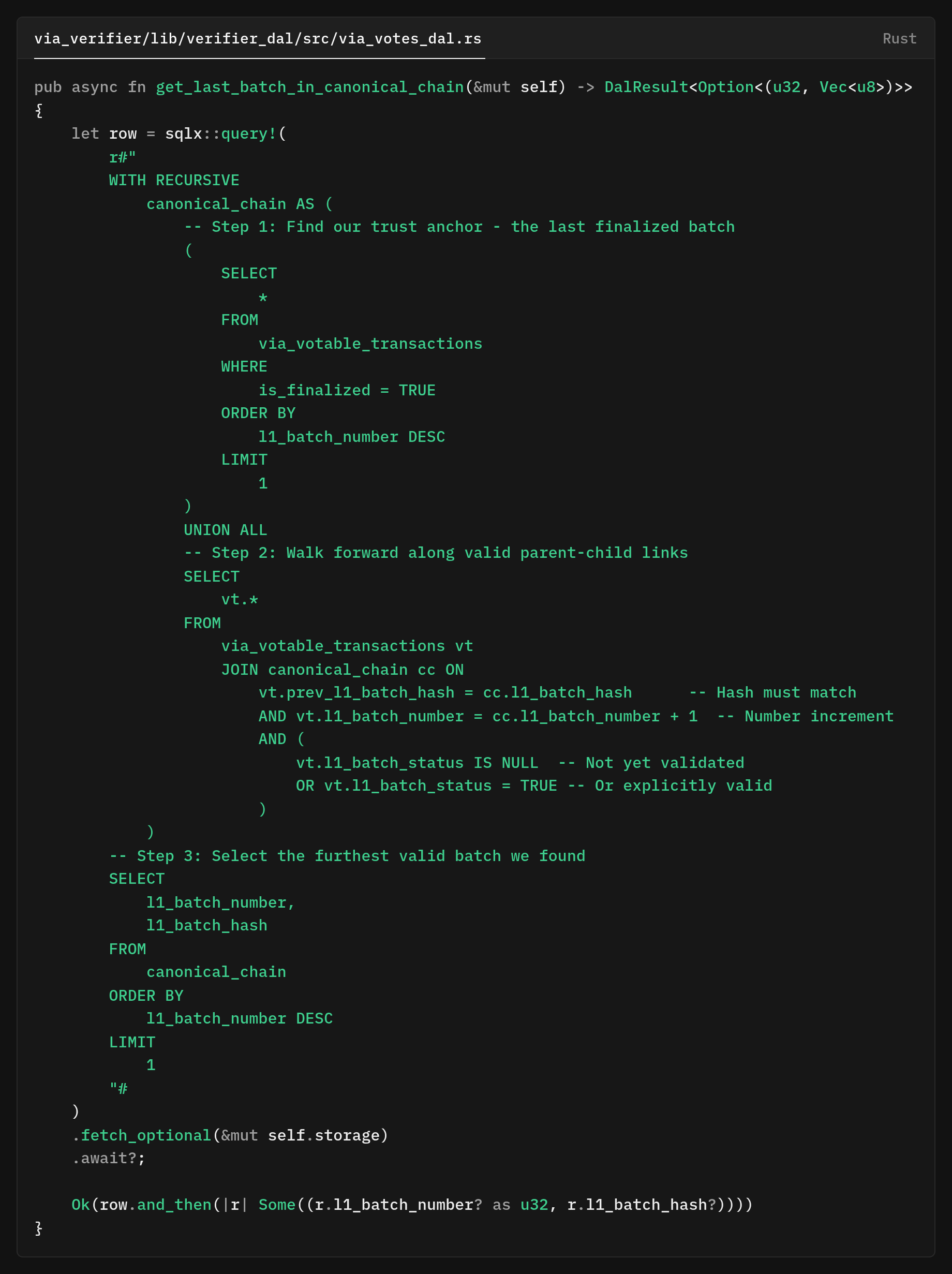
This implementation uses a recursive CTE to anchor at the last finalized batch end and then walk forward along valid, linked batches to find the current canonical head.
This design tolerates gaps due to rejected batches and only follows the sequence that satisfies both numbering and hash linkage.
What it computes
- Base/Anchor: Start at the most recently finalized batch. If there is none, the CTE yields no rows, and the helper returns
None. This makes “no head” an explicit state, which is useful for genesis/initialization. - Recursive step (forward traversal). From the anchor, recursively include batches where:
prev_l1_batch_hashequals theparent’s l1_batch_hash, andl1_batch_numberis exactlyparent.number + 1, andl1_batch_statusis eitherNULLorTRUE(i.e., not explicitly rejected).
After constructing the forward-closed subgraph, pick the maximum l1_batch_number in that set.
That row is the canonical head, the furthest batch reachable through strictly valid parent links from the last finalized anchor.
Why a forward recursion?
A common approach is to walk backward from the largest observed batch by following previous hashes until reaching a finalized root.
While this works, it is less selective and may do unnecessary work with many dangling, non-canonical tips. Anchoring at the last finalized batch and walking forward only accepts connected, valid batches per policy (status + numbering).
So the CTE naturally ignores orphaned or rejected branches. It’s also easy for PostgreSQL to speed up this process with indexes on the join keys.
- Single, connected path. The join ensures strict parent/child linkage (both by hash and by
+1numbering). Disconnected or skipped sequences are excluded. - Rejections respected. By requiring
l1_batch_status IS NULL OR TRUEthe recursion won’t traverse batches marked invalid. This is crucial during recovery/reorg scenarios. - Finalized-anchored. Finalization is used as a trust root; the recursion builds only on top of that root. If there is no finalized batch, the absence is explicit, and the caller can treat the system as “pre-genesis” or the bootstrap phase.
- The head is unique. The
ORDER BY … DESC LIMIT 1over the recursively discovered set yields exactly one head row, even if multiple candidates previously existed elsewhere in the table.
Performance and indexing
On realistic chains, recursion depth is the distance from the last finalized batch to the current head. This is typically small. To ensure the query is predictable under load:
- Indexes. Create B-tree indexes on:
via_votable_transactions(l1_batch_number)via_votable_transactions(l1_batch_hash)via_votable_transactions(prev_l1_batch_hash)
The canonical head directly informs batch acceptance. In the message processor via_verifier/node/via_btc_watch/src/message_processors/verifier.rs
After parsing the DA-reference, the verifier reads the batch’s claimed number and parent hash and compares them to the canonical head from the database:
- new.number == head.number + 1
- new.prev_hash == head.hash
If either check fails, the message is skipped as non-sequential or incorrectly linked. If both pass, the batch is eligible for insertion. This transforms the database into the arbiter of chain shape, while the payload is the arbiter of what the new batch claims to be
Special thanks to Idir TxFusion for being the co-author and original author of patch 221


