
Via Verifier Network Security Upgrade: Canonical Chain Selection Hardening

We’ve upgraded Via’s verifier selection logic to eliminate race-condition forks and drastically improve performance.
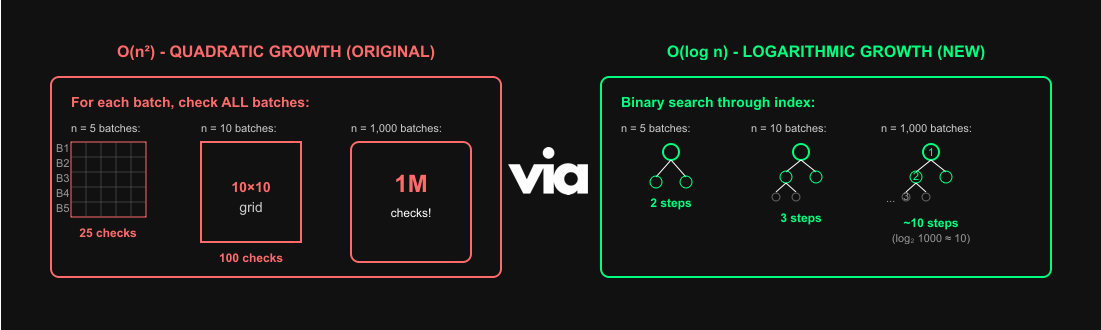
Part of Patch 221 hardens canonical chain selection by replacing correlated SQL subqueries with a CTE that finds the canonical chain tip in O(log n) time (instead of O(n²)) and prevents forks by enforcing strict parent-hash linkage.
This improvement ensures all verifiers follow the single canonical chain from genesis to tip, resulting in a single canonical chain with increased performance to handle a significant amount of batches, and removes the risk of parallel forks in mainnet.
Instead of relying on a correlated subquery for every candidate batch, the verifier now uses an index Common Table Expression (CTE) to find the canonical chain tip in O(log n) time and prevents forks or shadow chains caused by sequencer resets or network race conditions.
This post is a part of our larger PR
If you aren't familiar with Via yet, read our introduction blog post

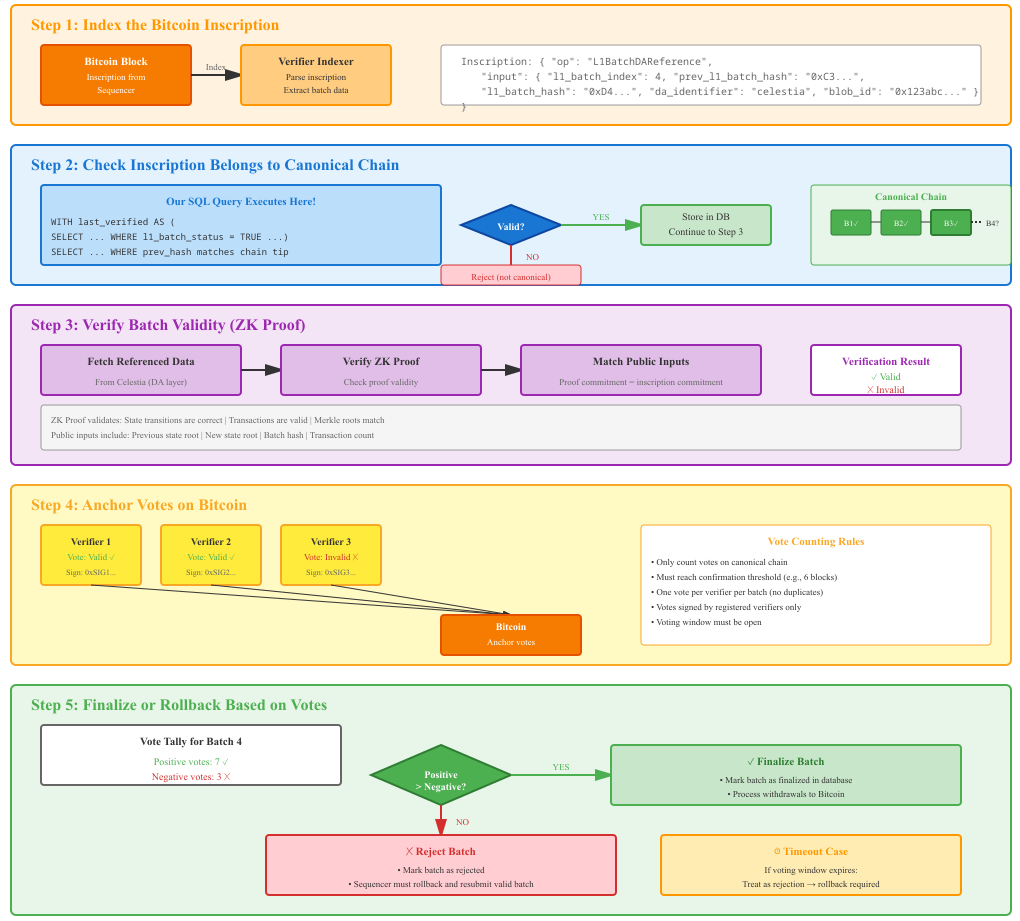
How the Verifier Should Work
- Index the Bitcoin inscription created by the sequencer.
- Check that the inscription belongs to the canonical chain; if valid, store it in the database.
- Verify batch validity: fetch referenced data, verify zk proof, and ensure the proof's public inputs match the inscript commitment using zk‑proof.
- After verification, each verifier anchors one signed vote on Bitcoin for this batch (valid or invalid). Count only votes on the canonical chain that have reached the confirmation threshold and enforce one vote per verifier per betch
- Finalize or rollback based on votes:
- If positive votes > negative votes, the network processes withdrawals.
- If negative votes prevail, or the voting window times out, reject the batch. The sequencer rolls back and submits a new valid L1 batch.
How did we come up with this improvement?
In blockchain systems, consensus is only as strong as the rules that enforce it. Via verifier network plays a key role in ensuring the validity of the data posted by the sequencer by doing ZK verification and canonical chain validation. During testing, our team identified that under certain conditions, a verifier could accept a forked chain as valid.
During a recent devnet redeployment, we reset the sequencer from genesis while keeping the verifier network running. The expected behavior is that the verifier network should ignore all new batches and wait for a new valid batch. But we noticed something strange. Our verifier network didn't did not force the canonical chain but created a new chain from batch 1.
The verifier's role is to ensure that every batch processed belongs to the canonical batch chain. But we discovered a scenario where it would validate only the inscription, assuming the sequencer created a valid batch, without fully verifying its position in the canonical chain. Combined with a bug in the SQL logic, this allowed the insertion of a new batch with number 1 without validating the canonical chain.
The verifier network must only follow the single canonical chain and must never restart from genesis
While harmless in our devnet environment, this bug poses a correctness issue that, in production, could cause a verifier’s chain to fork and potentially lead to user fund loss. To prevent this, we rigorously test our code before mainnet launch to ensure the verifier network consistently validates a single canonical chain, enforces honest behavior from the sequencer, and never restarts verification from genesis.
The problem was compounded by performance degradation. The query to select the next batch for verification was taking increasingly longer as the chain grew.
The problem? Buried in via_votes_dal.rs with a correlated subquery that was performing a full table scan for every potential batch candidate.
Under load, it could trigger race conditions and timeouts, creating the exact conditions that could trigger verification behavior, leading to a possible 'shadow chain'.
The original implementation used a EXISTS subquery to verify chain continuity. For every unverified batch, it would scan the entire table to check if a valid parent existed.
Complexity? O(n²)
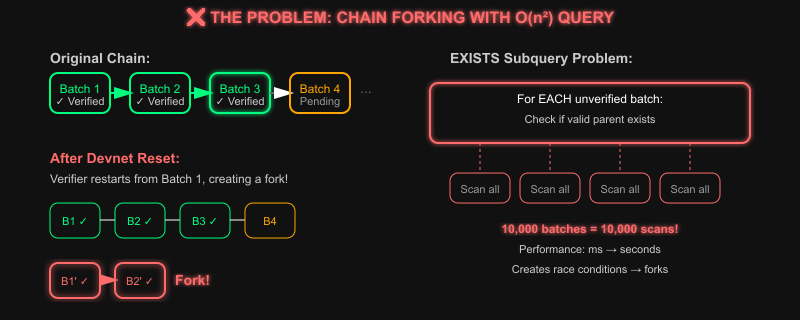
This query was trying to find the next batch to verify by using a correlated subquery EXIST for every unverified batch (v1) as it would run a separate subquery to check if a valid parent batch (v2) existed. This approach had several flaws. First, the performance degraded exponentially as the chain grew. For a chain with 10,000 batches, this could mean 10,000 separate executions.
Second, the logic was vulnerable to race conditions where multiple batches could appear valid simultaneously, leading to the chain fork we saw in our devnet reset.
A simple join could work, but wouldn't express the recursive natural chain traversal. Materialized views would add operational complexity to our deployment process.
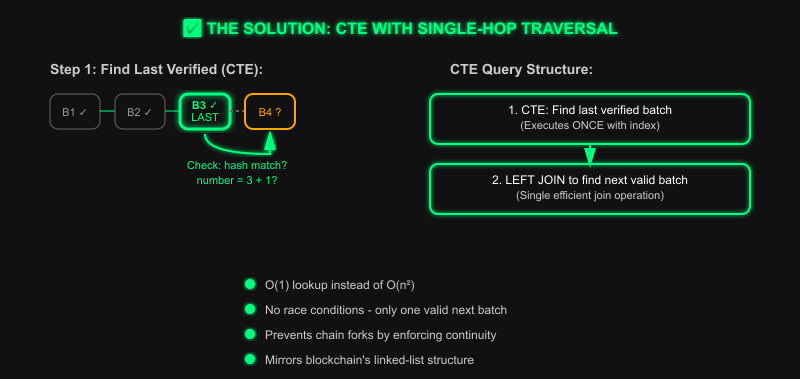
Recursive Common Table Expressions
Our solution was to use recursive Common Table Expressions CTEs , which is an SQL feature. A perfect fit for walking a blockchain structure in SQL.
Traditional Nested Subqueries:
┌─────────────┐
│ Main Query │
└──────┬──────┘
│
├─► For EACH row, execute:
│ ┌─────────────┐
│ │ Subquery 1 │
│ └─────────────┘
│ ┌─────────────┐
│ │ Subquery 2 │
│ └─────────────┘
│
▼
[Result]
CTEs:
┌─────────────┐
│ CTE 1 │ ─── Execute ONCE
└──────┬──────┘
│
▼
┌─────────────┐
│ CTE 2 │ ─── Execute ONCE
└──────┬──────┘
│
▼
┌─────────────┐
│ Main Query │ ─── Use pre-computed results
└──────┬──────┘
│
▼
[Result]The idea is to make the database query mirror how a validator actually works. Start from the last verified batch, step forward exactly one batch, and efficiently find the next candidate. No more guessing, and no more scanning the entire table for every candidate.
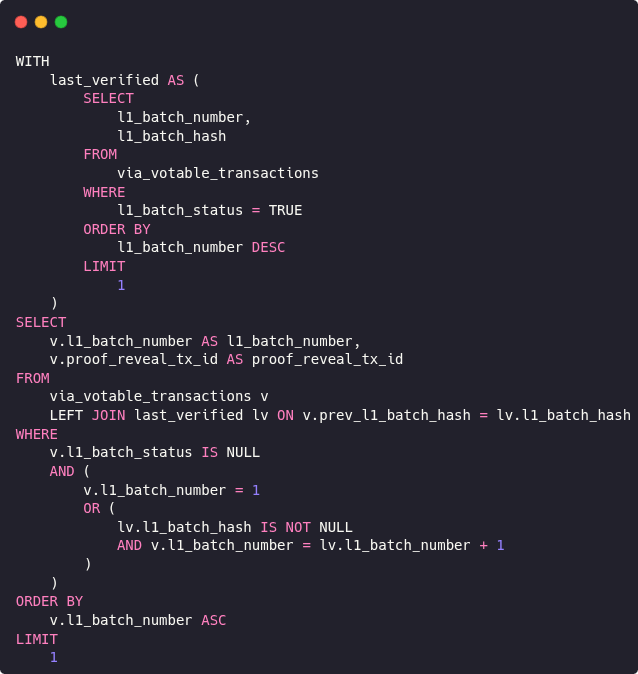
The new implementation uses a Common Table Expression (CTE) named last_verified to isolate the tip of the current verified chain that is the most recent batch where l1_batch_status = TRUE
Joins unverified batches (v) with the last verified one (lv), matching on v.prev_batch_hash = lv.l1_batch_hash
While we filter for the genesis batch (l1_batch_number = 1) or the next valid batch in sequence (v.l1_batch_number = lv.l1_batch_number + 1) where the parent hash matches the tip.
This structure models the chain like a linked list anchored from the last known valid point. It avoids full table scans on every candidate batch, unlike the original EXISTS query, and prevents race conditions because only one batch can match the join condition with the verified tip at a time. You might notice it's not a fully recursive CTE (no repeated traversal from genesis to top) but a "trip forward" traversal, a single-hop recursive step which is perfect for chain progression where only the next batch matters.
CTEs performance
As pointed out before, this CTE executes only once, and there's a notable performance difference from the original implementation. The old query had a fatal inefficiency, as it would for every unverified batch run a separate subquery check to check the parent, exploding into a classic O(n²) complexity as the chain grew.

With our new CTE approach, the database executes the last_verified query just once at the beginning and reuses it throughout the main query execution. This single execution, compared to the old repeated execution.
This single execution drastically reduces computational overhead and is the reason the performance improvement is so dramatic.
WITH
last_verified AS (
SELECT
l1_batch_number,
l1_batch_hash
FROM
via_votable_transactions
WHERE
l1_batch_status = TRUE
ORDER BY
l1_batch_number DESC
LIMIT
1
)
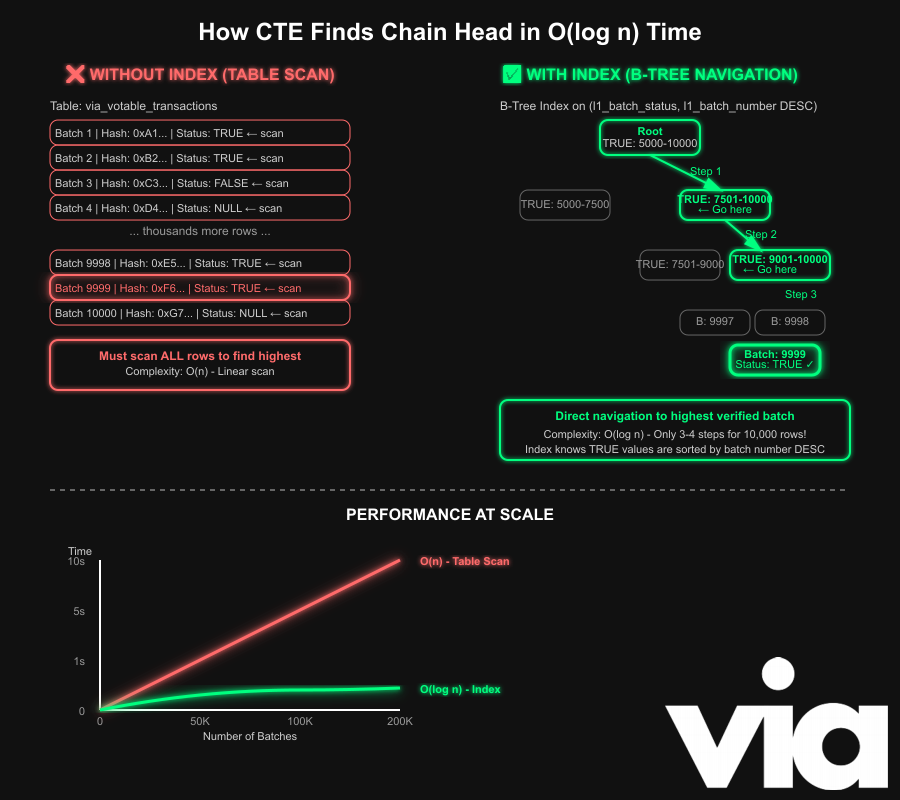
The O(log n) complexity comes from how databases use indexes to answer our specific query pattern.
When we run
SELECT l1_batch_number
FROM via_votable_transactions
WHERE l1_batch_status = TRUE
ORDER BY l1_batch_number DESC
LIMIT 1We are basically asking, "What's the highest batch number among all verified batches?"
With a composite index on (l1_batch_status, l1_batch_number), the database uses a B-Tree to group all TRUE entries together within that group and keep them ordered by l1_batch_number which lets the planner skip any table scan.
It can jump straight to the end of the TRUE section in the index and return the top value without extra sorting or filtering. The lookup is now O(log n) and in practice, near constant time due to the B-Tree pointer navigation and caching. To visualize this
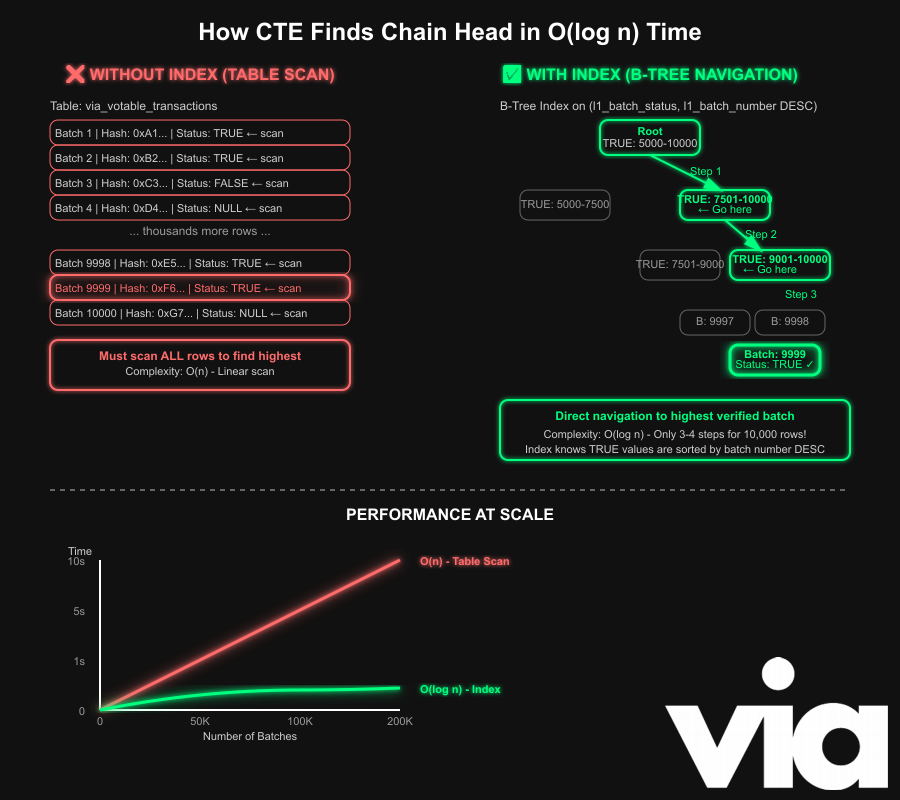
The beauty of this is that the database jumps straight toTRUEsection on the index in logarithmic time, then immediately retrieve the last entry in that section, which is already sorted by batch number, as there's no need to scan batches withTRUEorNULLand no need to sort theTRUEentries because the index maintains ordering inherently.
This now efficient operation results in multiple benefits. The minimal IO load means we're reading just a few index pages rather than potentially thousands of data pages from the main table.
We reduced both disk activity and memory pressure on the database server. The performance remains stable and predictable even if the chain grows.
Whether we have 10k batches or 1 million batches, the query time increases so slowly due to the logarithmic growth that it feels almost constant in practice.
Most importantly, this approach ensures deterministic behavior by always returning exactly one row representing the canonical chain tip, getting rid of the race conditions that plagued the original implementation.
But knowing the tip of the chain is only half the job. Once we have it, the verifier needs to determine with certainty which unverified batch should follow. This is where the main query comes in. Let's go over the next part of the SQL query
One batch at a time
Once the CTE has pinpointed the chain tip, the main query's job is to find exactly one unverified batch that should be verified next
SELECT
v.l1_batch_number AS l1_batch_number,
v.proof_reveal_tx_id AS proof_reveal_tx_id
FROM
via_votable_transactions v
LEFT JOIN last_verified lv ON v.prev_l1_batch_hash = lv.l1_batch_hash
WHERE
v.l1_batch_status IS NULL
AND (
v.l1_batch_number = 1
OR (
lv.l1_batch_hash IS NOT NULL
AND v.l1_batch_number = lv.l1_batch_number + 1
)
)
ORDER BY
v.l1_batch_number ASC
LIMIT
1;This section must be deterministic across all verifier nodes to maintain consensus and must enforce the rules that every match must cryptographically link to its predecessor to maintain ordering.
The main query pulls this off with a set up LEFT JOIN between unverified batches and the current chain tip. Using a LEFT JOIN instead of an INNER JOIN makes the genesis case work. When no batches have been verified yet, the CTE for the chin tip returns nothing, but the LEFT JOIN still allows the genesis batch (v.l1_batch_number = 1) to be selected and kick off the chain.
Hash continuity: v.prev_l1_batch_hash = lv.l1_batch_hash (The batch must cryptographically link to the tip)
Sequence continuity: v.l1_batch_number = lv.l1_batch_number + 1 (Has to be exactly the next batch in the sequence)
Both of these conditions matter. It is not enough for a batch to simply follow numerically. We need to ensure it's also cryptographically tied to the previous one, and that's what the hash check guarantees.
Likewise, matching the hash alone isn’t enough either. Without the correct sequence number, you could link to an older or out-of-order batch.
Together, this enforces strict linearity. As these checks stop forks and prevent skipped batches.
Our WHERE handles two scenarios with a single condition. For the genesis batch (v.l1_batch_number = 1), no parent validation is needed because the genesis has no predecessor, obviously.
For all other batches, the query requires both successful hash linking (lv.l1_batch_hash IS NOT NULL, confirming that JOIN it found its match, and sequential ordering (v.l1_batch_number = lv.l1_batch_number + 1).
The ORDER BY v.l1_batch_number ASC LIMIT 1 makes sure that if multiple valid candidates do exist (which should only happen during initial chain bootstrap when both genesis and batch 1 might be unverified), the lowest numbered batch is always selected first to keep a consistent verification order across all nodes.
This query changed from a previous O(n²) operation, which caused verifier chain forks, to an efficient O(log n) operation with chain integrity.

The original implementation used a correlated subquery with EXIST which checked the unverified batch against every other batch repeatedly, which not only caused performance issues as the chain grew but also introduced race conditions that could lead to duplicate verification and a fork.
What was once a quadratic mess by rechecking every unverified batch against all others is now a clean, index query, which mirrors how a chain should work, tip first, strictly linear.
The CTE acts like a validator memory, as it holds onto the current head of the chain. Only verify what logically extends instead of everything & pray.
The use of the LEFT_JOIN not only removes the need for branching logic but also handles cold-start scenarios. When the verifier is empty, the query doesn't panic. Instead, it selects the genesis batch.
Performance-wise?
It's a win across the board. One index lookup gives us the chain tip. One indexed join narrows the unverified candidates. The rest is filtering and ordering.
Security is stronger
- The verifier now processes only inscriptions confirmed on the canonical Bitcoin chain, after the required confirmation depth. This prevents forked or invalid branches from being introduced into the verifier index.
The old code flaw was its EXISTS subquery that checked if "any" parent chain existed somewhere in the database. This created a bug/vulnerability where during a reset, the verifier could start verifying batch 1 again even though a valid chain existed. The subquery would find no parent for batch 1 (since there's no batch 0), which allowed it to pass validation and create a fork
The new code eliminates this bug and potential vulnerability with a source of truth last_verified CTE that identifies exactly one canonical chain tip. Now every match must either be a genesis batch or must link to this specific tip. This removes the ambiguity of which chain is canonical or not. A malicious actor or buggy sequencer cannot inject a forked chain because any batch not linking to the with the lv.l1_batch_hash IS NOT NULL check.
Finality is preserved
If the verifier accidentally created a parallel chain, there could be a case of two different batches being verified simultaneously, one on the original chain and one on the forked chain. Both might accumulate votes and potentially trigger withdrawals, leading to double-spending or loss of funds.
The new code improvement makes this impossible since only batches that extend the canonical chain can pass validation. The check v.l1_batch_number = lv.l1_batch_number + 1 ensures strict sequential ordering from the established tip.
Now, withdrawals can only be processed from batches that are provably part of the signal canonical chain, avoiding the possibility of conflicting withdrawal instructions.
- L1 batches are finalized only after receiving a majority of positive confirmed votes on the canonical chain. Withdrawals are processed solely from finalized batches.
Code improvements
Separation of Concerns: The CTE cleanly separates "finding the chain state" from "validating the next batch." This makes the code more maintainable and easier to reason about.
Performance: Moving from O(n²) correlated subqueries to O(log n) index operation isn't only a performance win but also an architectural improvement, which prevents the system from degrading over time and avoids creating potential timeout-induced race conditions.
The canonical chain selection logic was rewritten from correlated subqueries to recursive CTEs, yielding semantics for ancestry/canonicality, fewer round-trips, and simpler reorg handling
Database records retain both canonical and non-canonical inscriptions with explicit flags and ancestry metadata, making the system auditable and deterministic under reorgs
This elegant solution shows our engineers delivered a fix that not only solves the problem but also improves and strengthens verification. How a careful query design can enforce invariants for a distributed verifier network at the database level.

Special thanks to Idir TxFusion for being the co-author and original author of patch 221
Try out our Alpha Testnet Bridge with the Xverse BTC wallet by getting free Testnet BTC to bridge: https://docs.onvia.org/user-guide/bridge-btc-between-bitcoin-and-via
🔗 Github: https://github.com/vianetwork
👥 Discord: https://discord.gg/ReS5cz8M6H
📚 Documentation: https://docs.onvia.org
⚙️ Via Core: https://github.com/vianetwork/via-core
🛠️ Via SDK: https://npmjs.com/package/@vianetwork/via-ethers
🌐 Website: https://buildonvia.org
𝕏 Twitter: https://x.com/buildonvia
🧭 Explorer: https://testnet.blockscout.onvia.org
Code snippets
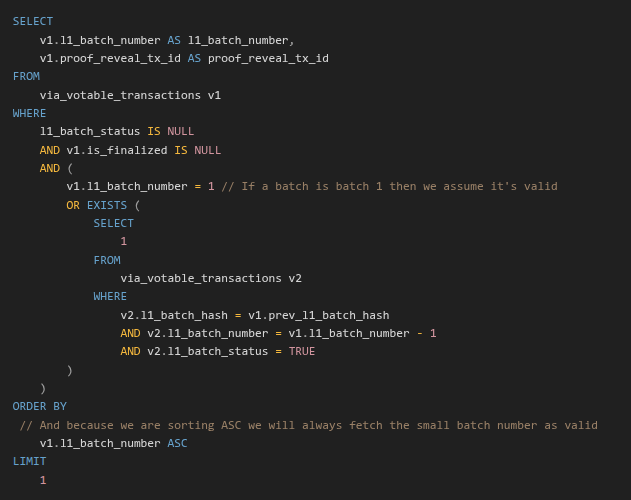
Original Code:
SELECT
v1.l1_batch_number AS l1_batch_number,
v1.proof_reveal_tx_id AS proof_reveal_tx_id
FROM
via_votable_transactions v1
WHERE
l1_batch_status IS NULL
AND v1.is_finalized IS NULL
AND (
v1.l1_batch_number = 1
OR EXISTS (
SELECT
1
FROM
via_votable_transactions v2
WHERE
v2.l1_batch_hash = v1.prev_l1_batch_hash
AND v2.l1_batch_number = v1.l1_batch_number - 1
AND v2.l1_batch_status = TRUE
)
)
ORDER BY
v1.l1_batch_number ASC
LIMIT
1
New Code:
WITH
last_verified AS (
SELECT
l1_batch_number,
l1_batch_hash
FROM
via_votable_transactions
WHERE
l1_batch_status = TRUE
ORDER BY
l1_batch_number DESC
LIMIT
1
)
SELECT
v.l1_batch_number AS l1_batch_number,
v.proof_reveal_tx_id AS proof_reveal_tx_id
FROM
via_votable_transactions v
LEFT JOIN last_verified lv ON v.prev_l1_batch_hash = lv.l1_batch_hash
WHERE
v.l1_batch_status IS NULL
AND (
v.l1_batch_number = 1
OR (
lv.l1_batch_hash IS NOT NULL
AND v.l1_batch_number = lv.l1_batch_number + 1
)
)
ORDER BY
v.l1_batch_number ASC
LIMIT
1


